
Seminário Técnico da TSMC na América do Norte 2026: Interpretação sobre divisão de lógica avançada, adiamento do High-NA e avanço em encapsulamento


Índice
- 1. Primeira conclusão: Não é apenas uma atualização de roadmap, mas a TSMC está proativamente bifurcando os processos avançados
- 2. Organizando o roadmap: Quais marcos estão no “plataforma de duração”, quais estão para “servir AI”
- 3. A13 e N2U: O que a TSMC realmente quer vender não é apenas um único nó, mas uma “plataforma reutilizável por anos”
- 4. A16 e A12: O verdadeiro gargalo de AI/HPC já migrou da miniaturização frontal para fornecimento de energia e fiação
- 5. Postergando High-NA EUV: Não se trata de cautela, mas de uma típica decisão de fabricação ao estilo da TSMC
- 6. O verdadeiro diferencial está na embalagem: A Lei de Moore está se tornando uma história a nível de pacote
- 7. COUPE e fotônica de silício: Interconexão de AI entra da dúvida do “cobre aguentar” para “colaboração fotônica-eletrônica viável”
- 8. Meu julgamento de investimento: O que a TSMC esclareceu agora é a estrutura de lucros dos próximos três anos, não apenas o roadmap técnico
Interpretação do Seminário Técnico da TSMC 2026 América do Norte: Bifurcação lógica de ponta, adiamento High-NA e prioridade para embalagem
A maior mudança neste seminário não é simplesmente a criação de novos marcos, mas o fato de a TSMC dividir formalmente a lógica avançada em dois caminhos: o segmento móvel/cliente continua buscando compatibilidade de design, longevidade da plataforma e otimização de ROI, enquanto AI/HPC coloca abastecimento de energia traseira, fiação sistêmica, embalagem avançada e fotônica de silício no centro das competências. A13 e N2U representam “fazer do 2nm uma plataforma”, A16 e A12 representam “transferir o gargalo de chips AI da miniaturização de transistores para fornecimento de energia e integração sistêmica”.
Baseado no artigo original de SemiVision 2026-04-23 “Resumo dos principais pontos do Seminário Técnico da TSMC América do Norte 2026”, sem múltipla validação cruzada por bancos de investimento; a seguir, a versão em chinês reorganizada e meus comentários adicionais. 404K Semi-AI | 2026-04-23
1. Primeira conclusão: Não é apenas uma atualização de roadmap, mas a TSMC está proativamente bifurcando os processos avançados
Olhando apenas para os títulos das notícias, este seminário técnico parece repetir a narrativa familiar dos últimos anos: nomes como A13, A12, N2U, além da afirmação de “não usar High-NA EUV até 2029”. Mas o que realmente merece uma reavaliação não é o nome de um nó, mas sim o fato de a TSMC reconhecer publicamente:Lógica avançada não serve mais para atender todos os terminais através de um caminho único.
SoC móvel e aceleradores de AI enfrentam hoje dois conjuntos completamente diferentes de limitações físicas. O primeiro ainda valoriza consumo, área, integração de sinal analógico/misto, reutilização de IP e ritmo de tape-out; o segundo enfrenta gargalos cada vez maiores de densidade de corrente, queda IR, densidade térmica, oportunidades de fiação traseira, fornecimento de energia a nível de embalagem e economia de largura de banda sistêmica. Em outras palavras, a narrativa passada de “quem chega primeiro ao próximo nó vence” está sendo substituída por “quem consegue organizar melhor transistores, energia, embalagem e integração sistêmica”.
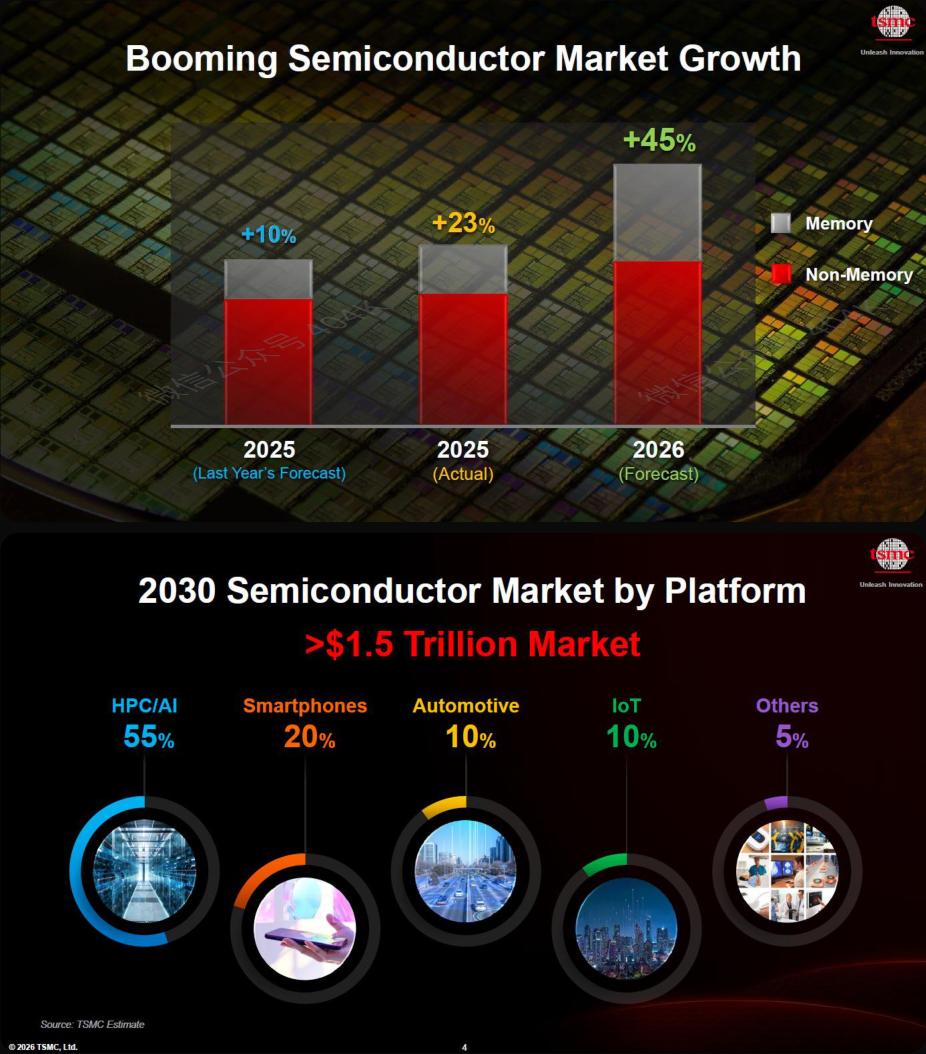
Imagem original: Curva de crescimento do mercado de semicondutores mudou de PC, internet e smartphones para expansão compressiva dirigida por AI
Meu julgamento central é:A TSMC não está apenas atualizando o roadmap de nós, mas proativamente redefinindo as combinações de processos ideais para diferentes grupos de clientes. Isso trará dois resultados. Primeiro, o ponto de referência de avaliação dos processos avançados não será apenas densidade de transistor, mas também longevidade da plataforma e custo de migração do cliente. Segundo, a vantagem competitiva na era da AI migrará rapidamente do front-end logic para embalagem, fotônica de silício e fornecimento sistêmico de energia.
2. Organizando o roadmap: Quais marcos estão no “plataforma de duração”, quais estão para “servir AI”
| A13 | Depois de A14 | Densidade lógica cerca de 6% maior que A14, mantendo regras de design e compatibilidade elétrica | Voltado para móvel/cliente, redução óptica de baixo impacto e baixo custo de migração |
| N2P | Principal evolução da família 2nm | Mesmas regras de design que N2; em relação ao N3E, 18% mais rápido ao mesmo consumo, 36% menos consumo ao mesmo desempenho, densidade lógica 1,2x | Base de produção em massa da plataforma 2nm, suporte à adoção mais ampla |
| N2U | Meta de produção em massa em 2028 | Em relação ao N2P, 3-4% mais rápido ao mesmo consumo, 8-10% menos consumo ao mesmo desempenho, 2-3% de aumento de densidade lógica, mantendo compatibilidade IP N2P | Usa o ecossistema 2nm mais maduro para prolongar a plataforma, maximizando ROI |
| N2X | Branch de desempenho da família N2 | Células padrão de ultra-alto desempenho + dispositivos de alta velocidade, totalizando cerca de 10% de ganho em velocidade | Oferece entrada para clientes de desempenho que não querem migrar imediatamente para fornecimento traseiro |
| A16 | Previsão de produção em massa em 2027 | Introduz Super Power Rail para fornecimento traseiro, voltado para aplicações de alto desempenho em data center | Ponto crítico na direção AI/HPC, resolve gargalos de energia e fiação |
| A12 | Plano de produção em massa em 2029 | A seguir do A16, continua miniaturizando frente e verso | Não é apenas “mais avançado”, mas aprofunda ainda mais o fornecimento traseiro |
| High-NA EUV | Não adotado antes de 2029 | TSMC confirmou postergar para após 2029 | ROI tem prioridade sobre liderança de equipamento, maximizando a utilização do EUV atual |
| Embalagem avançada | 2028-2029 | Em 2028, suporte para 10 chips de computação (UTC+8) + 20 pilhas de memória (UTC+8); SoW-X em produção em 2029 | A fronteira do desempenho migrou do chip único para sistemas multi-chip |
| COUPE fotônica de silício | Progresso contínuo | Primeira geração de COUPE com bom progresso; eficiência energética da versão de substrato 4x (UTC+8), melhoria de latência em 10x (UTC+8); versão de camada intermediária com eficiência 10x (UTC+8), latência 20x melhor (UTC+8) | Fotônica de silício não é “projeto acadêmico”, mas parte da plataforma de interconexão AI |
O mais importante desta tabela não são os dados em si, mas o esclarecimento das prioridades da TSMC:A13/N2U/N2P/N2X resolvem continuidade de plataforma e custo de migração do cliente, A16/A12 resolvem os verdadeiros gargalos sistêmicos dos chips AI.
Citação original: "A13 is not radical. That is exactly why it matters."
3. A13 e N2U: O que a TSMC realmente quer vender não é apenas um único nó, mas uma “plataforma reutilizável por anos”
Pelo ponto de vista comercial, A13 e N2U podem ser tão relevantes quanto A16. Sua característica comum não é “o mais radical”, mas “o mais reutilizável”. A13 mantém as regras de design e compatibilidade elétrica com A14, dizendo ao cliente: não é necessário refazer todo o IP, EDA, aprovação e processo de confiabilidade por causa de um novo nome, e ainda pode obter benefícios de densidade. N2U vai além, expandindo o ecossistema N2 de um único nó para um ativo de plataforma usado por múltiplos ciclos de produto.
Isso é especialmente importante para mobile e clientes. Hoje, o custo de migração de equipes de SoC para novos processos é muito mais que o preço da bolacha, mas sim custos da infraestrutura de design: migração de IP, ajuste do fluxo EDA, revalidação de células padrão, adaptação de analógico, fechamento de timing, adaptação de software e riscos no ritmo de lançamento. O verdadeiro valor de A13 e N2U é permitir que os clientes diluam esses custos “sunk” em mais gerações de produtos.
Por isso, prefiro entender N2U como “camada de monetização da plataforma 2nm”. Não pretende substituir N2P, mas prolongar a vida econômica da família N2, permitindo à TSMC continuar extraindo valor de rendimento, ecossistema e compatibilidade de bibliotecas sem pressionar os clientes para migração total. Quanto mais forte essa habilidade, menos a TSMC parece uma empresa “vendendo wafers avançados”, e mais uma foundry de plataforma operando o ROI completo ao longo do ciclo de vida do cliente.
4. A16 e A12: O verdadeiro gargalo de AI/HPC já migrou da miniaturização frontal para fornecimento de energia e fiação
Se A13 e N2U são “escalonamento econômico mais inteligente”, A16 e A12 são a outra pista: chips AI não podem continuar apenas com abastecimento frontal convencional e fiação para ganho incremental.
A razão é simples. Aceleradores de AI estão cada vez maiores, corrente cada vez mais alta, hotspots cada vez mais concentrados, fornecimento de energia a nível de embalagem cada vez mais apertados. Neste estágio, o problema não é só velocidade de comutação de transistor, mas simse conseguimos fornecer energia limpa, extrair sinais com eficiência e controlar calor e largura de banda sistêmica. A atração da energia suministrada por trás está em tratar power e signal routing separadamente, liberando espaço de fiação frontal e melhorando resistência e congestionamento em caminhos críticos.
A TSMC posiciona A16 claramente para aplicações de alto desempenho em data centers, usando Super Power Rail para solucionar problemas sistêmicos, mostrando que a administração considera as restrições AI parte da definição do nó. A12 sinaliza que essa linha não será apenas um “teste de energia traseira”, mas continuará miniaturizando frente e verso juntos. Para AI/HPC isso é mais relevante do que apenas reduzir ainda mais o transistor.
Meu julgamento:A16/A12 não são “nós mais avançados” no sentido tradicional, mas pontos de reconstrução sistêmica da infraestrutura de AI pela TSMC. Isso elevará a barreira dos processos avançados do lead de litografia para arquitetura de entrega de energia, técnicas de embalagem e co-design sistêmico.
Citação original: "For AI infrastructure, the frontier is shifting from pure transistor shrink toward power-delivery architecture."
5. Postergando High-NA EUV: Não se trata de cautela, mas de uma típica decisão de fabricação ao estilo da TSMC
O ponto mais importante para reconsideração de preço de mercado do seminário é: TSMC reafirma claramente:Até 2029, A13 e A12 não pretendem usar High-NA EUV.
Muitos entendem isso como “tecnicamente não agressivo”, mas prefiro interpretar como uma típica decisão TSMC. High-NA é realmente uma das técnicas de litografia mais cruciais na próxima fase, mas implica maior CapEx, máscaras e integração mais complexas, exigências de ecossistema atualizadas e ROI mais incerto. A resposta da TSMC é direta: se o EUV atual ainda consegue entregar a miniaturização requerida de maneira econômica, não há motivo para substituir apenas pelo “rótulo tecnológico de liderança”.
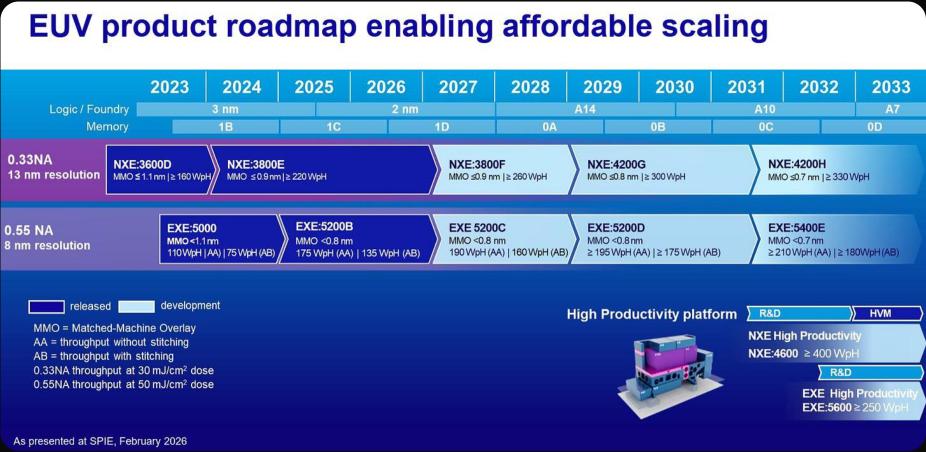
Imagem original: Roadmap High-NA EUV contrastando fortemente com a escolha da TSMC em continuar extraindo valor do EUV atual
Isso revela dois tipos de filosofia industrial. Intel enfatiza adoção antecipada do High-NA, TSMC foca em maximizar rendimento, disciplina de custo, maturidade do ecossistema e capacidade de escala dos projetos clientes com o EUV atual. Para investidores, não basta mais relacionar “quem adota o equipamento mais novo” com “quem é mais forte”. Num cenário de CapEx crescente e exigência de rendimento dos clientes,decisão de manufatura é diferencial.
Meu adicional: no curto prazo, High-NA é mais uma opção futura do que faixa de lucro dos próximos 2-3 anos; o que está sendo realizado é a maximização do uso do EUV atual, e a prioridade da TSMC para embalagem avançada, fornecimento de energia e interconexão.
Citação original: "If existing EUV can still deliver the needed scaling economically, then early adoption of High-NA is not automatically a virtue."
6. O verdadeiro diferencial está na embalagem: A Lei de Moore está se tornando uma história a nível de pacote
Ao olhar apenas para o roadmap de nós, é fácil subestimar o significado geral do seminário. A TSMC enfatiza que até 2028 sua capacidade de embalagem avançada suportará até10 chips de computação grandes (UTC+8) + 20 pilhas de memória (UTC+8) num sistema; SoW-X previsto para produção em massa em 2029. Esse sinal é crucial, pois mostra que a fronteira do desempenho é definida por “lógica + HBM + camada intermediária + gerenciamento térmico + fornecimento de energia + interconexão sistêmica”, não mais por um chip único.
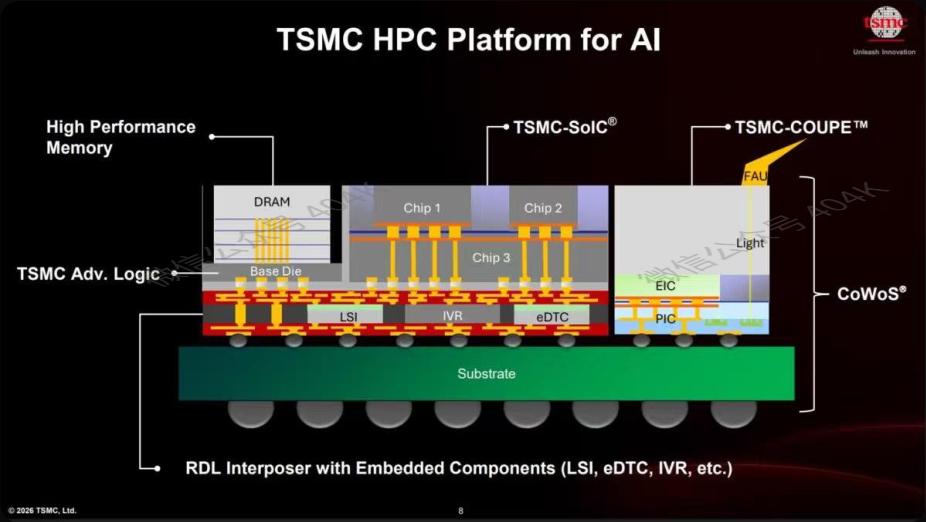
Imagem original: Plataforma AI/HPC da TSMC já trata lógica avançada, SoIC, COUPE e CoWoS como pilha unificada
Por isso, “empresa de semicondutores mais avançada” não tem mais a mesma definição. Antes era o menor transistor e melhor PPA; agora, o conceito é: quem consegue integrar transistor technology, power delivery, advanced packaging, manufaturabilidade e escala de produção ao cliente em um sistema que possa ser entregue em massa.
Para a TSMC, essa transição é naturalmente favorável, pois nunca vendeu apenas um nó, mas opera um sistema completo de processo, design, embalagem e colaboração com o cliente. Na era AI, com chips maiores, HBM empilhado, alto consumo e interconexão, o fosso competitivo da TSMC só aumenta, expandindo do front-end para toda a stack do sistema.
7. COUPE e fotônica de silício: Interconexão de AI entra da dúvida do “cobre aguentar” para “colaboração fotônica-eletrônica viável”
O último ponto, muitas vezes ignorado mas de grande valor médio, é o progresso da plataforma COUPE de fotônica de silício. TSMC não trata fotônica de silício como projeto de laboratório, mas inclui ativamente no roadmap de embalagem, com descrição do progresso da primeira geração COUPE.
A lógica é direta: gargalo de AI não é apenas densidade de computação, mas eficiência de movimentação de dados chip-chip, pacote-pacote, rack-rack. Quando o custo e a latência do cobre ficam altos, fotônica de silício e CPO deixam de ser “opções” e se tornam “necessidade para escalonamento”.
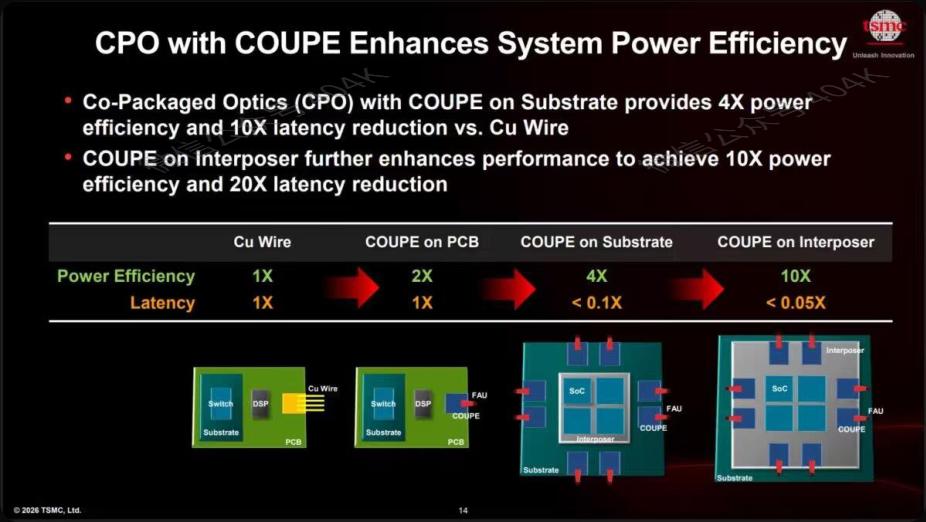
Imagem original: Eficiência energética e melhoria de latência do COUPE em substrato e camada intermediária mostram que fotônica de silício já chegou ao estágio de engenharia viável
Pelo gráfico, o caminho escolhido pela TSMC é claro: versão de substrato COUPE traz cerca de 4x eficiência energética comparado ao cobre (UTC+8) e 10x menor latência (UTC+8); versão de camada intermediária chega a 10x eficiência (UTC+8) e 20x menor latência (UTC+8). Mesmo que esses números dependam das condições reais de fabricação, já mostram:Fotônica de silício passou do “linguagem acadêmica” para “linguagem de plataforma”.
Meu julgamento: essa linha tem grande significado médio para a TSMC, pois expande a empresa de “fabricante lógico avançado” para núcleo de integração sistêmica AI. Quando isso se consolidar, o mercado não poderá mais avaliar TSMC apenas por ASP de wafer ou participação em processos avançados.
8. Meu julgamento de investimento: O que a TSMC esclareceu agora é a estrutura de lucros dos próximos três anos, não apenas o roadmap técnico
Se tivesse que resumir toda a informação do seminário em uma frase, seria:A TSMC está redefinindo a competição em processos avançados para uma disputa de “longevidade da plataforma + capacidade de fornecimento AI + capacidade de embalagem avançada + capacidade de interconexão fotônica”.
Isso traz três diferenciações para a cadeia de indústria:
- A primeira beneficiada é a própria TSMC e a cadeia AI centrada em CoWoS, SoIC, HBM, placas avançadas e embalagem sistêmica.
- A segunda se beneficia da continuação da maximização do EUV atual pela TSMC e disciplina de capital; o instrumento High-NA só será realizado no futuro, foco está na extração do EUV e ecossistema vigente.
- A terceira é fotônica de silício/CPO/interconexão sistêmica, que pode passar de “investimento temático” para “restrição de infraestrutura” se AI continuar escalando.
Se tivesse que apontar o maior alpha do relatório, não seria um parâmetro específico, mas o fato de a TSMC finalmente tornar público um fato oculto há anos:Os semicondutores avançados do futuro não triunfarão apenas por transistores menores, mas por maior capacidade de engenharia sistêmica. Isso mudará métodos de avaliação de nós, prioridades de CapEx, e o modo como o mercado enxerga “quem é o verdadeiro núcleo de infraestrutura AI”.

Aviso Legal: o conteúdo deste artigo reflete exclusivamente a opinião do autor e não representa a plataforma. Este artigo não deve servir como referência para a tomada de decisões de investimento.
Talvez também goste
Ouro a 4600 dólares, afinal, está caro ou não?

D (D) amplitude de 41,1% em 24 horas: especulação volátil em mercados de baixa liquidez
IR (InfraredFinance) oscila 118,0% em 24 horas: volume de negociações dispara e lidera forte volatilidade de preços