
DeepSeek R1 發布一周年,不卷功能、不融資、不著急,硬控了科技世界

顯示原文
作者:爱范儿
「伺服器繁忙,請稍後再試。」 一年前,我也是被這句話硬控的用戶之一。  DeepSeek 帶著 R1 在一年前的昨天(2025.1.20)橫空出世,一登場就吸引了全球的目光。 那時候為了能順暢用上 DeepSeek,我翻遍了自部署教程,也下載過不少號稱「XX - DeepSeek 滿血版」的各類應用。
DeepSeek 帶著 R1 在一年前的昨天(2025.1.20)橫空出世,一登場就吸引了全球的目光。 那時候為了能順暢用上 DeepSeek,我翻遍了自部署教程,也下載過不少號稱「XX - DeepSeek 滿血版」的各類應用。  一年後,說實話,我打開 DeepSeek 的頻率少了很多。 豆包能搜尋、能生圖,千問接入了淘寶和高德,元寶有即時語音對話和微信公眾號的內容生態;更不用說海外的 ChatGPT、Gemini 等 SOTA 模型產品。 當這些全能 AI 助手把功能列表越拉越長時,我也很現實地問自己:「有更方便的,為什麼還要守著 DeepSeek?」 於是,DeepSeek 在我的手機裡從第一屏掉到了第二屏,從每天必開變成了偶爾想起。 看一眼 App Store 的排行榜,這種「變心」又似乎不是我一個人的錯覺。
一年後,說實話,我打開 DeepSeek 的頻率少了很多。 豆包能搜尋、能生圖,千問接入了淘寶和高德,元寶有即時語音對話和微信公眾號的內容生態;更不用說海外的 ChatGPT、Gemini 等 SOTA 模型產品。 當這些全能 AI 助手把功能列表越拉越長時,我也很現實地問自己:「有更方便的,為什麼還要守著 DeepSeek?」 於是,DeepSeek 在我的手機裡從第一屏掉到了第二屏,從每天必開變成了偶爾想起。 看一眼 App Store 的排行榜,這種「變心」又似乎不是我一個人的錯覺。 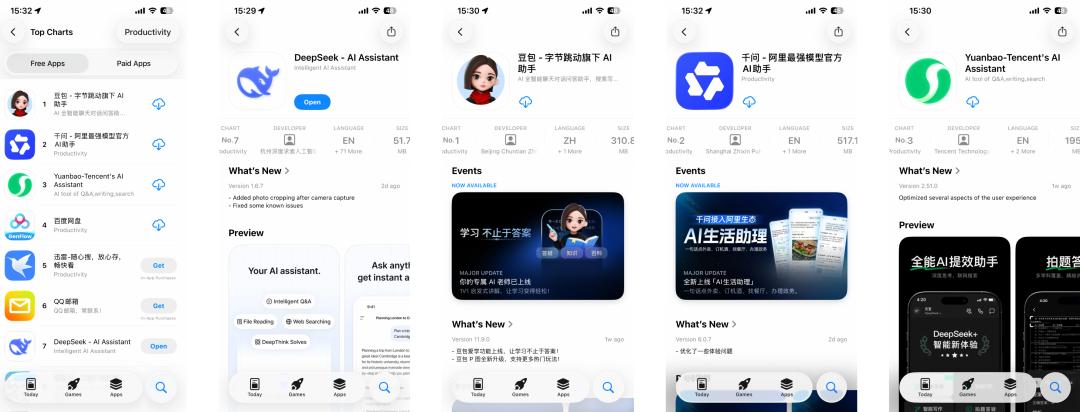 免費應用下載榜的前三名,已經被國產互聯網大廠的「御三家」包攬,而曾經霸榜的 DeepSeek,已經悄悄來到了第七名。 在一眾恨不得把全能、多模態、AI 搜尋寫在臉上的競品裡,DeepSeek 顯得格格不入,51.7 MB 的極簡安裝包,不追熱點,不捲宣發,甚至連視覺推理和多模態功能都還沒上。 但這正是最有意思的地方。表面上看,它似乎真的「掉隊」了,但實際上 DeepSeek 相關的模型調用仍是多數平台的首選。 而當我試圖總結 DeepSeek 過去這一年的動作,把視線從這個單一的下載榜單移開,去看全球的 AI 發展,了解為什麼它如此地不慌不忙,以及即將發布的 V4,又準備給這個行業帶來什麼新的震動; 我發現這個「第七名」對 DeepSeek 來說毫無含金量,它一直是那個讓巨頭們真正睡不著覺的「幽靈」。 掉隊?DeepSeek 有自己的節奏 當全球的 AI 巨頭都在被資本裹挾著,通過商業化來換取利潤時,DeepSeek 活得像是一個唯一的自由球員。看看它的競爭對手們,無論是國內剛剛港股上市的智譜和 MiniMax,還是國外瘋狂捲投資的 OpenAI 和 Anthropic。 為了維持昂貴的算力競賽,就連馬斯克都無法拒絕資本的誘惑,前幾天剛剛才為 xAI 融了 200 億美元。 但 DeepSeek 至今保持著「零外部融資」的紀錄。
免費應用下載榜的前三名,已經被國產互聯網大廠的「御三家」包攬,而曾經霸榜的 DeepSeek,已經悄悄來到了第七名。 在一眾恨不得把全能、多模態、AI 搜尋寫在臉上的競品裡,DeepSeek 顯得格格不入,51.7 MB 的極簡安裝包,不追熱點,不捲宣發,甚至連視覺推理和多模態功能都還沒上。 但這正是最有意思的地方。表面上看,它似乎真的「掉隊」了,但實際上 DeepSeek 相關的模型調用仍是多數平台的首選。 而當我試圖總結 DeepSeek 過去這一年的動作,把視線從這個單一的下載榜單移開,去看全球的 AI 發展,了解為什麼它如此地不慌不忙,以及即將發布的 V4,又準備給這個行業帶來什麼新的震動; 我發現這個「第七名」對 DeepSeek 來說毫無含金量,它一直是那個讓巨頭們真正睡不著覺的「幽靈」。 掉隊?DeepSeek 有自己的節奏 當全球的 AI 巨頭都在被資本裹挾著,通過商業化來換取利潤時,DeepSeek 活得像是一個唯一的自由球員。看看它的競爭對手們,無論是國內剛剛港股上市的智譜和 MiniMax,還是國外瘋狂捲投資的 OpenAI 和 Anthropic。 為了維持昂貴的算力競賽,就連馬斯克都無法拒絕資本的誘惑,前幾天剛剛才為 xAI 融了 200 億美元。 但 DeepSeek 至今保持著「零外部融資」的紀錄。 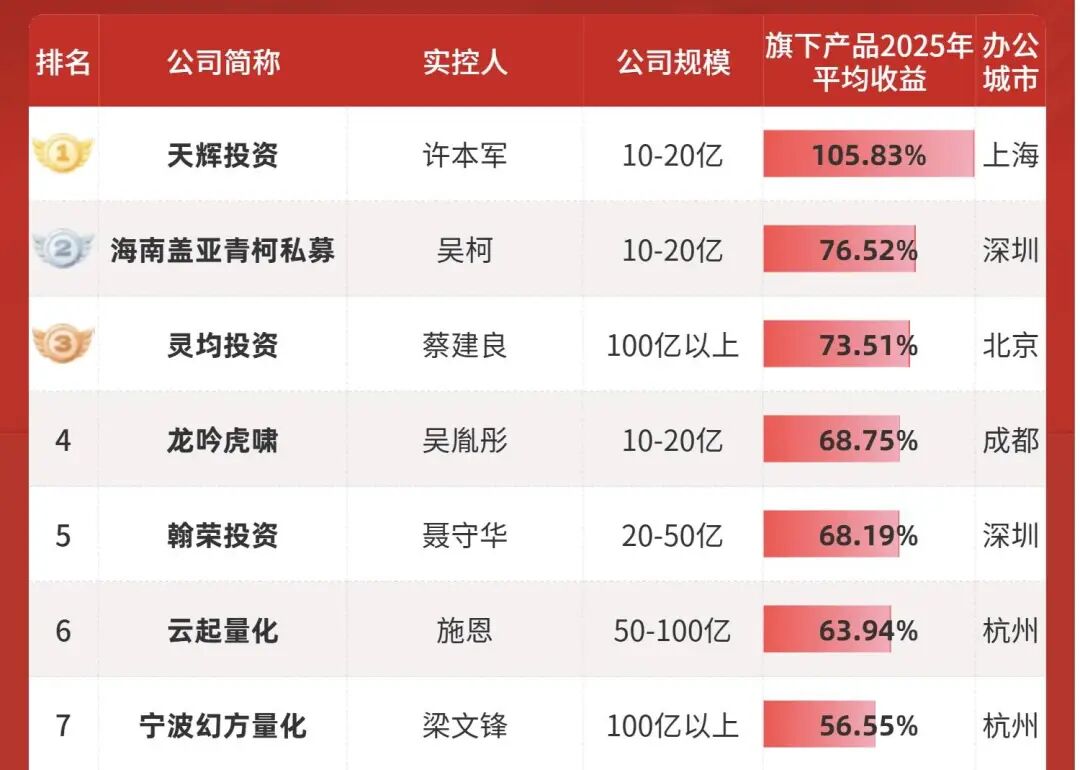 年度私募百強榜,按照公司平均收益排名,幻方量化位於第七名,百億以上規模排名第二 在這個所有人都急著變現、急著向投資人交作業的時代,DeepSeek 之所以敢掉隊,是因為它背後站著一台超級「印鈔機」,幻方量化。 作為 DeepSeek 的母公司,這家量化基金在去年實現了超高的 53% 回報率,利潤超過 7 億美元(約合人民幣 50 億元)。 梁文鋒直接用這筆老錢,來供養「DeepSeek AGI」的新夢。這種模式,也讓 DeepSeek 極其奢侈地擁有了對金錢的掌控權。
年度私募百強榜,按照公司平均收益排名,幻方量化位於第七名,百億以上規模排名第二 在這個所有人都急著變現、急著向投資人交作業的時代,DeepSeek 之所以敢掉隊,是因為它背後站著一台超級「印鈔機」,幻方量化。 作為 DeepSeek 的母公司,這家量化基金在去年實現了超高的 53% 回報率,利潤超過 7 億美元(約合人民幣 50 億元)。 梁文鋒直接用這筆老錢,來供養「DeepSeek AGI」的新夢。這種模式,也讓 DeepSeek 極其奢侈地擁有了對金錢的掌控權。 
沒有資方的指手畫腳。
沒有大公司病,許多拿了巨額融資的實驗室,陷入了紙面富貴的虛榮和內耗,就像最近頻頻爆出有員工離職的 Thinking Machine Lab;還有小扎的 Meta AI 實驗室各種緋聞。
只對技術負責, 因為沒有外部估值壓力,DeepSeek 不需要為了財報好看而急於推出全能 App,也不需要為了迎合市場熱點去捲多模態。它只需要對技術負責,而不是對財務報表負責。 App Store 的下載量排名,對於一家需要向 VC 證明「日活增長」的創業公司來說是命門。但對於一家只對 AI 發展負責、不僅不缺錢還不想被錢通過 KPI 控制的實驗室來說,這些有關市場的排名掉隊,或許正是它得以保持專注、免受外界噪音干擾的最佳保護色。 更何況,根據 QuestMobile 的報告,DeepSeek 的影響力完全沒有「掉隊」 改變生活,也影響了世界 AI 軍備競賽 即便 DeepSeek 可能根本不在意,我們是否已經選擇了其他更好用的 AI 應用,但它過去這一年帶來的影響,可以說各行各業都沒有錯過。 矽谷的「DeepSeek 震撼」 最開始的 DeepSeek,不僅僅是一個好用的工具,更像是一個風向標,用一種極其高效且低成本的方式,打碎了矽谷巨頭們精心編織的高門檻神話。
更何況,根據 QuestMobile 的報告,DeepSeek 的影響力完全沒有「掉隊」 改變生活,也影響了世界 AI 軍備競賽 即便 DeepSeek 可能根本不在意,我們是否已經選擇了其他更好用的 AI 應用,但它過去這一年帶來的影響,可以說各行各業都沒有錯過。 矽谷的「DeepSeek 震撼」 最開始的 DeepSeek,不僅僅是一個好用的工具,更像是一個風向標,用一種極其高效且低成本的方式,打碎了矽谷巨頭們精心編織的高門檻神話。  如果說一年前的 AI 競賽是比誰的顯卡多、誰的模型參數大,那麼 DeepSeek 的出現,硬生生把這場競賽的規則改寫了。在 OpenAI 及其內部團隊(The Prompt) 的最近發布總結回顧中,他們不得不承認, DeepSeek R1 的發布在當時給 AI 競賽帶來了「極大的震動(jolted)」,甚至被形容為一場「地震級的衝擊(seismic shock)」。 DeepSeek 一直在用實際行動證明,頂尖的模型能力,不需要天價的算力堆砌。 根據 ICIS 情報服務公司最近的分析,DeepSeek 的崛起徹底打破了算力決定論。它向世界展示了,即使在晶片受到限制、成本極其有限的情況下,依然可以訓練出性能比肩美國頂尖系統的模型。
如果說一年前的 AI 競賽是比誰的顯卡多、誰的模型參數大,那麼 DeepSeek 的出現,硬生生把這場競賽的規則改寫了。在 OpenAI 及其內部團隊(The Prompt) 的最近發布總結回顧中,他們不得不承認, DeepSeek R1 的發布在當時給 AI 競賽帶來了「極大的震動(jolted)」,甚至被形容為一場「地震級的衝擊(seismic shock)」。 DeepSeek 一直在用實際行動證明,頂尖的模型能力,不需要天價的算力堆砌。 根據 ICIS 情報服務公司最近的分析,DeepSeek 的崛起徹底打破了算力決定論。它向世界展示了,即使在晶片受到限制、成本極其有限的情況下,依然可以訓練出性能比肩美國頂尖系統的模型。  這直接導致了全球 AI 競賽從「造出最聰明的模型」,轉向了「誰能把模型做得更高效、更便宜、更易於部署」。 微軟報告裡的「另類」增長 當矽谷巨頭們還在爭奪付費訂閱用戶時,DeepSeek 也開始在被巨頭遺忘的地方扎根。 在微軟上週發布的《2025 全球 AI 普及報告》中,DeepSeek 的崛起被列為 2025 年「最意想不到的發展之一」。報告揭示了一個有意思的數據:
這直接導致了全球 AI 競賽從「造出最聰明的模型」,轉向了「誰能把模型做得更高效、更便宜、更易於部署」。 微軟報告裡的「另類」增長 當矽谷巨頭們還在爭奪付費訂閱用戶時,DeepSeek 也開始在被巨頭遺忘的地方扎根。 在微軟上週發布的《2025 全球 AI 普及報告》中,DeepSeek 的崛起被列為 2025 年「最意想不到的發展之一」。報告揭示了一個有意思的數據:
非洲使用率高:因為 DeepSeek 的免費策略和開源屬性,消除了昂貴的訂閱費和信用卡門檻。它在非洲的使用率是其他地區的 2 到 4 倍。
佔領受限市場: 在那些美國科技巨頭難以觸及或服務受限的地區,DeepSeek 幾乎成了唯一的選擇。數據顯示,它國內的市場份額高達 89%,在白俄羅斯達到 56%,在古巴也有 49%。 微軟在報告裡也不得不承認,DeepSeek 的成功更加確定了,AI 的普及不僅取決於模型有多強,更取決於誰能用得起。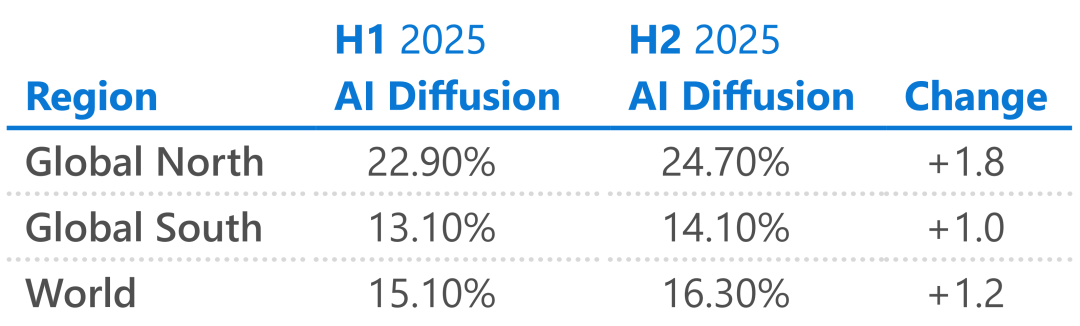 下一個十億級 AI 用戶,可能不會來自傳統的科技中心,而是來自 DeepSeek 覆蓋的這些地區。 歐洲:我們也要做 DeepSeek 不僅是矽谷,DeepSeek 的影響跨越了整個地球,歐洲也不例外。 歐洲一直是被動地使用美國的 AI,雖然也有自己的模型 Mistral,但一直不溫不火。DeepSeek 的成功讓歐洲人看到了一條新路,既然一家資源有限的中國實驗室能做到,歐洲為什麼不行?
下一個十億級 AI 用戶,可能不會來自傳統的科技中心,而是來自 DeepSeek 覆蓋的這些地區。 歐洲:我們也要做 DeepSeek 不僅是矽谷,DeepSeek 的影響跨越了整個地球,歐洲也不例外。 歐洲一直是被動地使用美國的 AI,雖然也有自己的模型 Mistral,但一直不溫不火。DeepSeek 的成功讓歐洲人看到了一條新路,既然一家資源有限的中國實驗室能做到,歐洲為什麼不行?  據連線雜誌最近的一篇報導,歐洲科技界正在掀起一場「打造歐洲版 DeepSeek」的競賽。不少來自歐洲的開發者,開始打造開源大模型,其中一個叫 SOOFI 的歐洲開源項目更是明確表示,「我們將成為歐洲的 DeepSeek。」 DeepSeek 過去這一年的影響,也加劇了歐洲對於「AI 主權」的焦慮。他們開始意識到,過度依賴美國的閉源模型是一種風險,而 DeepSeek 這種高效、開源的模式,正是他們需要的參照。 關於 V4,有這些信息值得關注 影響還在繼續,如果說一年前的 R1 是 DeepSeek 給 AI 行業的一次示範,那麼即將到來的 V4,會不會又是一次反常識的操作。 根據前段時間零零散散的爆料,和最近公開的技術論文,我們梳理了關於 V4 最值得關注的幾個核心信號。 1. 新模型 MODEL1 曝光
據連線雜誌最近的一篇報導,歐洲科技界正在掀起一場「打造歐洲版 DeepSeek」的競賽。不少來自歐洲的開發者,開始打造開源大模型,其中一個叫 SOOFI 的歐洲開源項目更是明確表示,「我們將成為歐洲的 DeepSeek。」 DeepSeek 過去這一年的影響,也加劇了歐洲對於「AI 主權」的焦慮。他們開始意識到,過度依賴美國的閉源模型是一種風險,而 DeepSeek 這種高效、開源的模式,正是他們需要的參照。 關於 V4,有這些信息值得關注 影響還在繼續,如果說一年前的 R1 是 DeepSeek 給 AI 行業的一次示範,那麼即將到來的 V4,會不會又是一次反常識的操作。 根據前段時間零零散散的爆料,和最近公開的技術論文,我們梳理了關於 V4 最值得關注的幾個核心信號。 1. 新模型 MODEL1 曝光
在 DeepSeek-R1 發布一週年之際,官方 GitHub 代碼庫意外曝光了代號為「MODEL1」的全新模型線索。 在代碼邏輯結構中,「MODEL1」是作為與「V32」(即 DeepSeek-V3.2)並列的獨立分支出現的,這一細節意味著「MODEL1」並不共享 V3 系列的參數配置或基礎架構,而是一個全新的、獨立的技術路徑。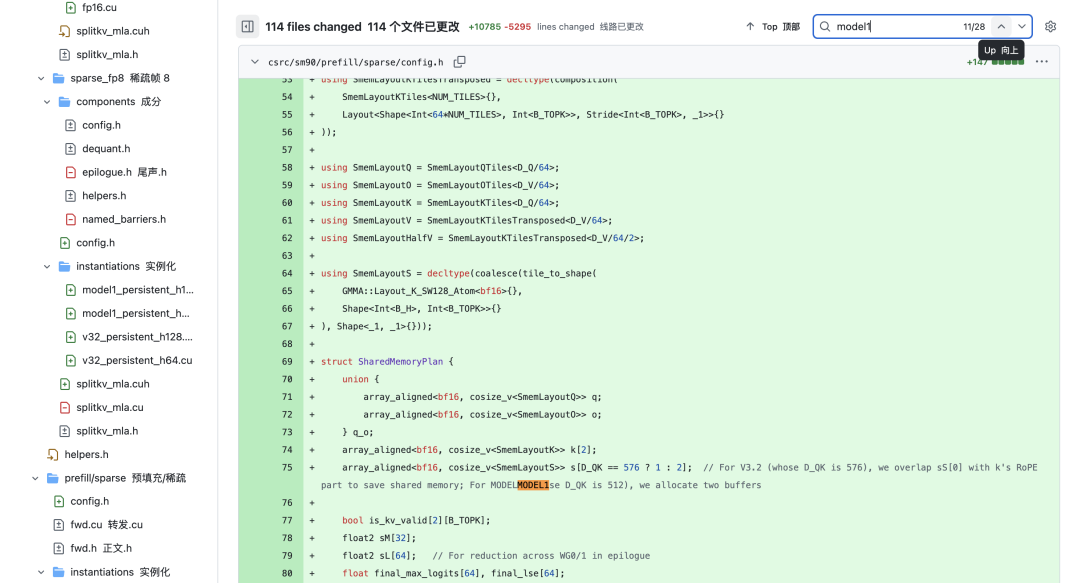 結合之前的爆料和洩露的代碼片段,我們梳理了「MODEL1」可能存在的技術特徵:
結合之前的爆料和洩露的代碼片段,我們梳理了「MODEL1」可能存在的技術特徵:  3. 核心能力是捲代碼和超長上下文 在通用對話已經趨於同質化的今天,V4 選擇了一個更硬核的突破口:生產力級別的代碼能力。 據接近 DeepSeek 的人士透露,V4 並沒有止步於 V3.2 在基準測試上的優異表現,而是在內部測試中,讓其代碼生成和處理能力,直接超越了 Anthropic 的 Claude 和 OpenAI 的 GPT 系列。
3. 核心能力是捲代碼和超長上下文 在通用對話已經趨於同質化的今天,V4 選擇了一個更硬核的突破口:生產力級別的代碼能力。 據接近 DeepSeek 的人士透露,V4 並沒有止步於 V3.2 在基準測試上的優異表現,而是在內部測試中,讓其代碼生成和處理能力,直接超越了 Anthropic 的 Claude 和 OpenAI 的 GPT 系列。  更關鍵的是,V4 試圖解決當前編程 AI 的一大痛點:「超長代碼提示詞」的處理。這意味著 V4 不再只是一個幫我們寫兩行腳本的助手,它試圖具備理解複雜軟件項目、處理大規模代碼庫的能力。 為了實現這一點,V4 也改進了訓練流程,確保模型在處理海量數據模式時,不會隨著訓練深入而出現「退化」。 4. 關鍵技術:Engram 比起 V4 模型本身,更值得關注的是 DeepSeek 在上週聯合北京大學團隊發表的一篇重磅論文。 這篇論文揭示了 DeepSeek 能夠在算力受限下持續突圍的真正底牌,是一項名為 「Engram(印跡/條件記憶)」 的新技術。
更關鍵的是,V4 試圖解決當前編程 AI 的一大痛點:「超長代碼提示詞」的處理。這意味著 V4 不再只是一個幫我們寫兩行腳本的助手,它試圖具備理解複雜軟件項目、處理大規模代碼庫的能力。 為了實現這一點,V4 也改進了訓練流程,確保模型在處理海量數據模式時,不會隨著訓練深入而出現「退化」。 4. 關鍵技術:Engram 比起 V4 模型本身,更值得關注的是 DeepSeek 在上週聯合北京大學團隊發表的一篇重磅論文。 這篇論文揭示了 DeepSeek 能夠在算力受限下持續突圍的真正底牌,是一項名為 「Engram(印跡/條件記憶)」 的新技術。 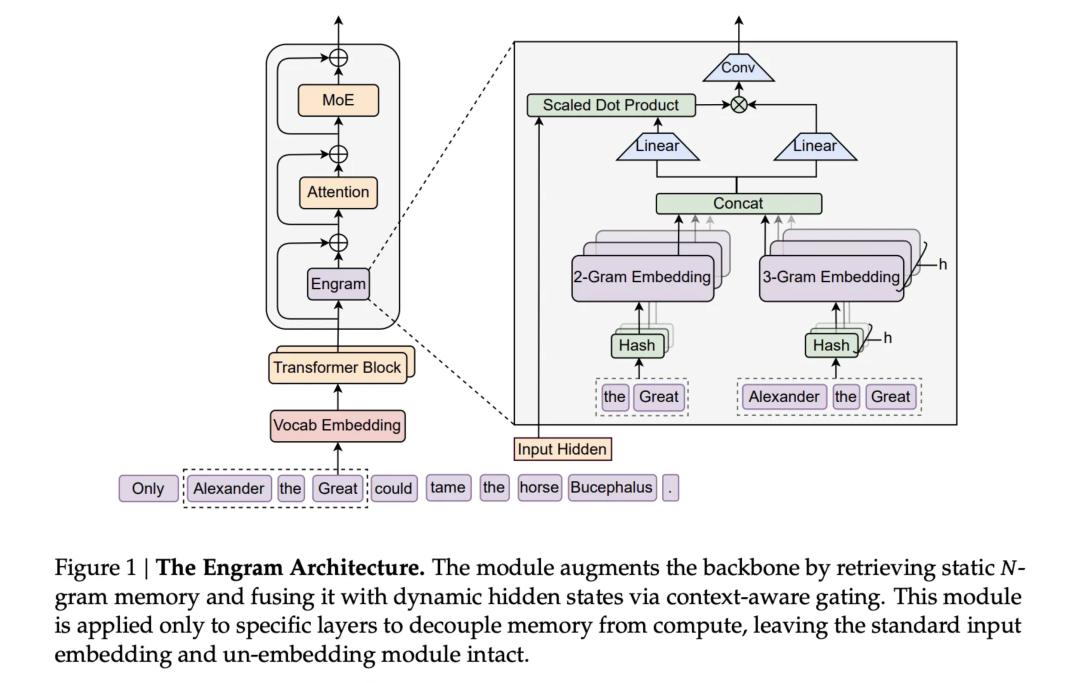 HBM(高頻寬內存)是全球 AI 算力競爭的關鍵領域之一,當對手都在瘋狂囤積 H100 顯卡來堆內存時,DeepSeek 再次走了一條不尋常的路。
HBM(高頻寬內存)是全球 AI 算力競爭的關鍵領域之一,當對手都在瘋狂囤積 H100 顯卡來堆內存時,DeepSeek 再次走了一條不尋常的路。
計算與記憶解耦: 現有的模型為了獲取基本信息,往往需要消耗大量昂貴的計算力來進行檢索。Engram 技術能讓模型高效地查閱這些信息,而不需要每次都浪費算力去計算 。
省下來的寶貴算力,被專門用於處理更複雜的高層推理。
研究人員稱,這種技術可以繞過顯存限制,支持模型進行激進的參數擴張,模型的參數規模可能進一步擴大。 在顯卡資源日趨緊張的背景下,DeepSeek 的這篇論文好像也在說,他們從未把希望完全寄託在硬體的堆砌上。 DeepSeek 這一年的進化,本質上是在用反常識的方式,解決 AI 行業的常識性難題。 它一年進帳 50 億,能夠用來訓練出上千個 DeepSeek R1,卻沒有一味捲算力,捲顯卡,也沒有傳出要上市,要融資的消息,反而開始去研究怎麼用便宜內存替代昂貴的 HBM。 過去一年,它幾乎是完全放棄了全能模型的流量,在所有模型廠商,每月一大更,每週一小更的背景下,專注推理模型,一次又一次完善之前的推理模型論文。 這些選擇,在短期看都是「錯的」。不融資,怎麼跟 OpenAI 拼資源?不做多模態的全能應用,生圖生影片,怎麼留住用戶?規模定律還沒失效,不堆算力,怎麼做出最強模型?
在顯卡資源日趨緊張的背景下,DeepSeek 的這篇論文好像也在說,他們從未把希望完全寄託在硬體的堆砌上。 DeepSeek 這一年的進化,本質上是在用反常識的方式,解決 AI 行業的常識性難題。 它一年進帳 50 億,能夠用來訓練出上千個 DeepSeek R1,卻沒有一味捲算力,捲顯卡,也沒有傳出要上市,要融資的消息,反而開始去研究怎麼用便宜內存替代昂貴的 HBM。 過去一年,它幾乎是完全放棄了全能模型的流量,在所有模型廠商,每月一大更,每週一小更的背景下,專注推理模型,一次又一次完善之前的推理模型論文。 這些選擇,在短期看都是「錯的」。不融資,怎麼跟 OpenAI 拼資源?不做多模態的全能應用,生圖生影片,怎麼留住用戶?規模定律還沒失效,不堆算力,怎麼做出最強模型?  但如果把時間線拉長,這些「錯的」選擇,可能正在為 DeepSeek 的 V4 和 R2 鋪路。 這就是DeepSeek的底色,在所有人都在捲資源的時候,它在捲效率;在所有人都在追逐商業化的時候,它在追逐技術極限。V4 會不會繼續這條路?還是會向「常識」妥協?答案或許就在接下來的幾週。 但至少現在我們知道,在 AI 這個行業裡,反常識,有時候才是最大的常識。 下一次,還是 DeepSeek 時刻。
但如果把時間線拉長,這些「錯的」選擇,可能正在為 DeepSeek 的 V4 和 R2 鋪路。 這就是DeepSeek的底色,在所有人都在捲資源的時候,它在捲效率;在所有人都在追逐商業化的時候,它在追逐技術極限。V4 會不會繼續這條路?還是會向「常識」妥協?答案或許就在接下來的幾週。 但至少現在我們知道,在 AI 這個行業裡,反常識,有時候才是最大的常識。 下一次,還是 DeepSeek 時刻。
DeepSeek 帶著 R1 在一年前的昨天(2025.1.20)橫空出世,一登場就吸引了全球的目光。 那時候為了能順暢用上 DeepSeek,我翻遍了自部署教程,也下載過不少號稱「XX - DeepSeek 滿血版」的各類應用。 一年後,說實話,我打開 DeepSeek 的頻率少了很多。 豆包能搜尋、能生圖,千問接入了淘寶和高德,元寶有即時語音對話和微信公眾號的內容生態;更不用說海外的 ChatGPT、Gemini 等 SOTA 模型產品。 當這些全能 AI 助手把功能列表越拉越長時,我也很現實地問自己:「有更方便的,為什麼還要守著 DeepSeek?」 於是,DeepSeek 在我的手機裡從第一屏掉到了第二屏,從每天必開變成了偶爾想起。 看一眼 App Store 的排行榜,這種「變心」又似乎不是我一個人的錯覺。 免費應用下載榜的前三名,已經被國產互聯網大廠的「御三家」包攬,而曾經霸榜的 DeepSeek,已經悄悄來到了第七名。 在一眾恨不得把全能、多模態、AI 搜尋寫在臉上的競品裡,DeepSeek 顯得格格不入,51.7 MB 的極簡安裝包,不追熱點,不捲宣發,甚至連視覺推理和多模態功能都還沒上。 但這正是最有意思的地方。表面上看,它似乎真的「掉隊」了,但實際上 DeepSeek 相關的模型調用仍是多數平台的首選。 而當我試圖總結 DeepSeek 過去這一年的動作,把視線從這個單一的下載榜單移開,去看全球的 AI 發展,了解為什麼它如此地不慌不忙,以及即將發布的 V4,又準備給這個行業帶來什麼新的震動; 我發現這個「第七名」對 DeepSeek 來說毫無含金量,它一直是那個讓巨頭們真正睡不著覺的「幽靈」。 掉隊?DeepSeek 有自己的節奏 當全球的 AI 巨頭都在被資本裹挾著,通過商業化來換取利潤時,DeepSeek 活得像是一個唯一的自由球員。看看它的競爭對手們,無論是國內剛剛港股上市的智譜和 MiniMax,還是國外瘋狂捲投資的 OpenAI 和 Anthropic。 為了維持昂貴的算力競賽,就連馬斯克都無法拒絕資本的誘惑,前幾天剛剛才為 xAI 融了 200 億美元。 但 DeepSeek 至今保持著「零外部融資」的紀錄。 年度私募百強榜,按照公司平均收益排名,幻方量化位於第七名,百億以上規模排名第二 在這個所有人都急著變現、急著向投資人交作業的時代,DeepSeek 之所以敢掉隊,是因為它背後站著一台超級「印鈔機」,幻方量化。 作為 DeepSeek 的母公司,這家量化基金在去年實現了超高的 53% 回報率,利潤超過 7 億美元(約合人民幣 50 億元)。 梁文鋒直接用這筆老錢,來供養「DeepSeek AGI」的新夢。這種模式,也讓 DeepSeek 極其奢侈地擁有了對金錢的掌控權。 沒有資方的指手畫腳。
沒有大公司病,許多拿了巨額融資的實驗室,陷入了紙面富貴的虛榮和內耗,就像最近頻頻爆出有員工離職的 Thinking Machine Lab;還有小扎的 Meta AI 實驗室各種緋聞。
只對技術負責, 因為沒有外部估值壓力,DeepSeek 不需要為了財報好看而急於推出全能 App,也不需要為了迎合市場熱點去捲多模態。它只需要對技術負責,而不是對財務報表負責。 App Store 的下載量排名,對於一家需要向 VC 證明「日活增長」的創業公司來說是命門。但對於一家只對 AI 發展負責、不僅不缺錢還不想被錢通過 KPI 控制的實驗室來說,這些有關市場的排名掉隊,或許正是它得以保持專注、免受外界噪音干擾的最佳保護色。
更何況,根據 QuestMobile 的報告,DeepSeek 的影響力完全沒有「掉隊」 改變生活,也影響了世界 AI 軍備競賽 即便 DeepSeek 可能根本不在意,我們是否已經選擇了其他更好用的 AI 應用,但它過去這一年帶來的影響,可以說各行各業都沒有錯過。 矽谷的「DeepSeek 震撼」 最開始的 DeepSeek,不僅僅是一個好用的工具,更像是一個風向標,用一種極其高效且低成本的方式,打碎了矽谷巨頭們精心編織的高門檻神話。 如果說一年前的 AI 競賽是比誰的顯卡多、誰的模型參數大,那麼 DeepSeek 的出現,硬生生把這場競賽的規則改寫了。在 OpenAI 及其內部團隊(The Prompt) 的最近發布總結回顧中,他們不得不承認, DeepSeek R1 的發布在當時給 AI 競賽帶來了「極大的震動(jolted)」,甚至被形容為一場「地震級的衝擊(seismic shock)」。 DeepSeek 一直在用實際行動證明,頂尖的模型能力,不需要天價的算力堆砌。 根據 ICIS 情報服務公司最近的分析,DeepSeek 的崛起徹底打破了算力決定論。它向世界展示了,即使在晶片受到限制、成本極其有限的情況下,依然可以訓練出性能比肩美國頂尖系統的模型。 這直接導致了全球 AI 競賽從「造出最聰明的模型」,轉向了「誰能把模型做得更高效、更便宜、更易於部署」。 微軟報告裡的「另類」增長 當矽谷巨頭們還在爭奪付費訂閱用戶時,DeepSeek 也開始在被巨頭遺忘的地方扎根。 在微軟上週發布的《2025 全球 AI 普及報告》中,DeepSeek 的崛起被列為 2025 年「最意想不到的發展之一」。報告揭示了一個有意思的數據: 非洲使用率高:因為 DeepSeek 的免費策略和開源屬性,消除了昂貴的訂閱費和信用卡門檻。它在非洲的使用率是其他地區的 2 到 4 倍。
佔領受限市場: 在那些美國科技巨頭難以觸及或服務受限的地區,DeepSeek 幾乎成了唯一的選擇。數據顯示,它國內的市場份額高達 89%,在白俄羅斯達到 56%,在古巴也有 49%。 微軟在報告裡也不得不承認,DeepSeek 的成功更加確定了,AI 的普及不僅取決於模型有多強,更取決於誰能用得起。
下一個十億級 AI 用戶,可能不會來自傳統的科技中心,而是來自 DeepSeek 覆蓋的這些地區。 歐洲:我們也要做 DeepSeek 不僅是矽谷,DeepSeek 的影響跨越了整個地球,歐洲也不例外。 歐洲一直是被動地使用美國的 AI,雖然也有自己的模型 Mistral,但一直不溫不火。DeepSeek 的成功讓歐洲人看到了一條新路,既然一家資源有限的中國實驗室能做到,歐洲為什麼不行? 據連線雜誌最近的一篇報導,歐洲科技界正在掀起一場「打造歐洲版 DeepSeek」的競賽。不少來自歐洲的開發者,開始打造開源大模型,其中一個叫 SOOFI 的歐洲開源項目更是明確表示,「我們將成為歐洲的 DeepSeek。」 DeepSeek 過去這一年的影響,也加劇了歐洲對於「AI 主權」的焦慮。他們開始意識到,過度依賴美國的閉源模型是一種風險,而 DeepSeek 這種高效、開源的模式,正是他們需要的參照。 關於 V4,有這些信息值得關注 影響還在繼續,如果說一年前的 R1 是 DeepSeek 給 AI 行業的一次示範,那麼即將到來的 V4,會不會又是一次反常識的操作。 根據前段時間零零散散的爆料,和最近公開的技術論文,我們梳理了關於 V4 最值得關注的幾個核心信號。 1. 新模型 MODEL1 曝光 在 DeepSeek-R1 發布一週年之際,官方 GitHub 代碼庫意外曝光了代號為「MODEL1」的全新模型線索。 在代碼邏輯結構中,「MODEL1」是作為與「V32」(即 DeepSeek-V3.2)並列的獨立分支出現的,這一細節意味著「MODEL1」並不共享 V3 系列的參數配置或基礎架構,而是一個全新的、獨立的技術路徑。
結合之前的爆料和洩露的代碼片段,我們梳理了「MODEL1」可能存在的技術特徵: - 代碼顯示其採用了與現行模型完全不同的 KV Cache 佈局策略,並在稀疏性(Sparsity)處理上引入了新機制。
- 在 FP8 解碼路徑上有多處針對性的內存優化調整,預示著新模型在推理效率和顯存佔用上可能有更好的表現。
- 此前爆料稱,V4 的代碼表現已超越 Claude 和 GPT 系列,並且具備處理複雜項目架構和大規模代碼庫的工程化能力。
3. 核心能力是捲代碼和超長上下文 在通用對話已經趨於同質化的今天,V4 選擇了一個更硬核的突破口:生產力級別的代碼能力。 據接近 DeepSeek 的人士透露,V4 並沒有止步於 V3.2 在基準測試上的優異表現,而是在內部測試中,讓其代碼生成和處理能力,直接超越了 Anthropic 的 Claude 和 OpenAI 的 GPT 系列。 更關鍵的是,V4 試圖解決當前編程 AI 的一大痛點:「超長代碼提示詞」的處理。這意味著 V4 不再只是一個幫我們寫兩行腳本的助手,它試圖具備理解複雜軟件項目、處理大規模代碼庫的能力。 為了實現這一點,V4 也改進了訓練流程,確保模型在處理海量數據模式時,不會隨著訓練深入而出現「退化」。 4. 關鍵技術:Engram 比起 V4 模型本身,更值得關注的是 DeepSeek 在上週聯合北京大學團隊發表的一篇重磅論文。 這篇論文揭示了 DeepSeek 能夠在算力受限下持續突圍的真正底牌,是一項名為 「Engram(印跡/條件記憶)」 的新技術。 HBM(高頻寬內存)是全球 AI 算力競爭的關鍵領域之一,當對手都在瘋狂囤積 H100 顯卡來堆內存時,DeepSeek 再次走了一條不尋常的路。 計算與記憶解耦: 現有的模型為了獲取基本信息,往往需要消耗大量昂貴的計算力來進行檢索。Engram 技術能讓模型高效地查閱這些信息,而不需要每次都浪費算力去計算 。
省下來的寶貴算力,被專門用於處理更複雜的高層推理。
研究人員稱,這種技術可以繞過顯存限制,支持模型進行激進的參數擴張,模型的參數規模可能進一步擴大。
在顯卡資源日趨緊張的背景下,DeepSeek 的這篇論文好像也在說,他們從未把希望完全寄託在硬體的堆砌上。 DeepSeek 這一年的進化,本質上是在用反常識的方式,解決 AI 行業的常識性難題。 它一年進帳 50 億,能夠用來訓練出上千個 DeepSeek R1,卻沒有一味捲算力,捲顯卡,也沒有傳出要上市,要融資的消息,反而開始去研究怎麼用便宜內存替代昂貴的 HBM。 過去一年,它幾乎是完全放棄了全能模型的流量,在所有模型廠商,每月一大更,每週一小更的背景下,專注推理模型,一次又一次完善之前的推理模型論文。 這些選擇,在短期看都是「錯的」。不融資,怎麼跟 OpenAI 拼資源?不做多模態的全能應用,生圖生影片,怎麼留住用戶?規模定律還沒失效,不堆算力,怎麼做出最強模型? 但如果把時間線拉長,這些「錯的」選擇,可能正在為 DeepSeek 的 V4 和 R2 鋪路。 這就是DeepSeek的底色,在所有人都在捲資源的時候,它在捲效率;在所有人都在追逐商業化的時候,它在追逐技術極限。V4 會不會繼續這條路?還是會向「常識」妥協?答案或許就在接下來的幾週。 但至少現在我們知道,在 AI 這個行業裡,反常識,有時候才是最大的常識。 下一次,還是 DeepSeek 時刻。 
0
0
免責聲明:文章中的所有內容僅代表作者的觀點,與本平台無關。用戶不應以本文作為投資決策的參考。
PoolX: 鎖倉獲得新代幣空投
不要錯過熱門新幣,且APR 高達 10%+
立即參與
您也可能喜歡
IN幣24小時內波動45%:低點0.074美元反彈至目前0.1059美元,尚未見公開可查的驅動事件
Bitget Pulse•2026/05/24 04:03
GRASS24小時內波動43.4%:AI敘事驅動價格大幅反彈
Bitget Pulse•2026/05/24 03:04
U2U24小時內波動89.4%:低流動性驅動極端價格震盪
Bitget Pulse•2026/05/24 02:18
TOWN24小時內波動94.3%:低市值代幣劇烈震盪,無明確24小時催化劑
Bitget Pulse•2026/05/24 01:56
加密貨幣價格
更多Bitcoin
BTC
$76,743.79
+1.58%
Ethereum
ETH
$2,120.27
+2.51%
Tether USDt
USDT
$0.9987
-0.01%
BNB
BNB
$656.46
+0.79%
XRP
XRP
$1.36
+1.46%
USDC
USDC
$0.9997
-0.00%
Solana
SOL
$85.92
+1.59%
TRON
TRX
$0.3629
-0.02%
Dogecoin
DOGE
$0.1029
+1.27%
Hyperliquid
HYPE
$59.97
+7.87%
如何出售 PI
Bitget 上架 PI:在 Bitget 上快速購買或出售 PI!
立即交易
還不是 Bitget 用戶嗎?新用戶可獲得價值 6,200 USDT 的迎新大禮包
立即註冊