
DeepSeek R1 feiert sein einjähriges Jubiläum: Kein Funktionswettlauf, keine Finanzierung, keine Eile – strikte Kontrolle der Technologiewelt
DeepSeek R1 feiert sein einjähriges Jubiläum: Kein Funktionswettlauf, keine Finanzierung, keine Eile – strikte Kontrolle der Technologiewelt

Original anzeigen
Von:爱范儿
„Server überlastet, bitte versuchen Sie es später erneut.“ Vor einem Jahr war auch ich einer der Nutzer, die von dieser Meldung ausgebremst wurden.  DeepSeek trat mit R1 am gestrigen Tag vor einem Jahr (20.01.2025) überraschend auf die Bühne und zog sofort weltweite Aufmerksamkeit auf sich. Damals habe ich sämtliche Self-Hosting-Anleitungen durchforstet und zahlreiche Apps ausprobiert, die sich „XX - DeepSeek Fullpower-Version“ nannten, nur um DeepSeek reibungslos nutzen zu können.
DeepSeek trat mit R1 am gestrigen Tag vor einem Jahr (20.01.2025) überraschend auf die Bühne und zog sofort weltweite Aufmerksamkeit auf sich. Damals habe ich sämtliche Self-Hosting-Anleitungen durchforstet und zahlreiche Apps ausprobiert, die sich „XX - DeepSeek Fullpower-Version“ nannten, nur um DeepSeek reibungslos nutzen zu können.  Ein Jahr später, um ehrlich zu sein, öffne ich DeepSeek deutlich seltener. Doubao kann suchen und Bilder generieren, Qianwen ist mit Taobao und Gaode verknüpft, Yuanbao bietet Echtzeit-Sprachdialoge und ein Content-Ökosystem für WeChat-Accounts; ganz zu schweigen von den SOTA-Modellprodukten wie ChatGPT und Gemini aus dem Ausland. Während diese All-in-One-AI-Assistenten ihre Funktionslisten immer weiter ausbauen, stelle ich mir ganz pragmatisch die Frage: „Wenn es etwas Bequemeres gibt, warum sollte ich dann noch bei DeepSeek bleiben?“ So ist DeepSeek auf meinem Handy von der ersten auf die zweite Seite gerutscht und von einer täglich geöffneten zu einer gelegentlich genutzten App geworden. Ein Blick auf das App Store-Ranking zeigt, dass diese „Abkehr“ offenbar nicht nur mein persönlicher Eindruck ist.
Ein Jahr später, um ehrlich zu sein, öffne ich DeepSeek deutlich seltener. Doubao kann suchen und Bilder generieren, Qianwen ist mit Taobao und Gaode verknüpft, Yuanbao bietet Echtzeit-Sprachdialoge und ein Content-Ökosystem für WeChat-Accounts; ganz zu schweigen von den SOTA-Modellprodukten wie ChatGPT und Gemini aus dem Ausland. Während diese All-in-One-AI-Assistenten ihre Funktionslisten immer weiter ausbauen, stelle ich mir ganz pragmatisch die Frage: „Wenn es etwas Bequemeres gibt, warum sollte ich dann noch bei DeepSeek bleiben?“ So ist DeepSeek auf meinem Handy von der ersten auf die zweite Seite gerutscht und von einer täglich geöffneten zu einer gelegentlich genutzten App geworden. Ein Blick auf das App Store-Ranking zeigt, dass diese „Abkehr“ offenbar nicht nur mein persönlicher Eindruck ist. 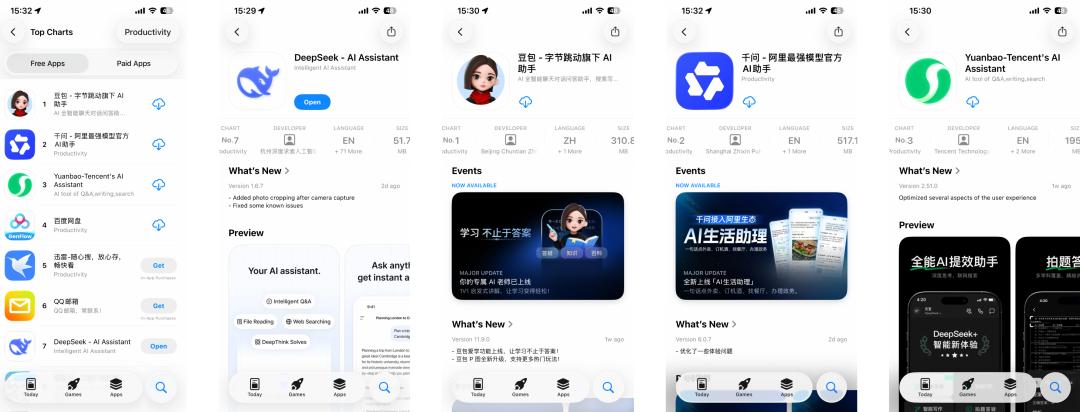 Die Top Drei der kostenlosen App-Downloads werden bereits von den „drei Großen“ der inländischen Internetgiganten dominiert, während das einst führende DeepSeek still und leise auf Platz sieben abgerutscht ist. Inmitten der Konkurrenz, die ihre Allround-, Multimodal- und AI-Suchfähigkeiten am liebsten auf die Stirn schreiben würde, wirkt DeepSeek mit seinem minimalistischen 51,7-MB-Installationspaket, ohne Trendjagd und ohne aufwendige Promotion, sogar ohne visuelle Schlussfolgerung und Multimodalität, geradezu aus der Zeit gefallen. Doch genau das ist das Interessante daran. Oberflächlich betrachtet scheint es wirklich „abgehängt“ zu sein, doch tatsächlich bleibt das DeepSeek-Modell weiterhin die erste Wahl der meisten Plattformen. Als ich versuchte, DeepSeeks Aktivitäten des vergangenen Jahres zusammenzufassen und meinen Blick von dieser einzelnen Downloadliste auf die globale AI-Entwicklung zu lenken, um zu verstehen, warum es so gelassen bleibt und was das bald erscheinende V4 für neue Impulse in die Branche bringen wird, stellte ich fest, dass dieser „siebte Platz“ für DeepSeek keinerlei Bedeutung hat – es ist nach wie vor das „Gespenst“, das die großen Player nachts wach hält. Abgehängt? DeepSeek hat seinen eigenen Rhythmus Während die globalen AI-Giganten vom Kapital getrieben werden und durch Kommerzialisierung Profite erzielen müssen, wirkt DeepSeek wie ein einziger freier Akteur. Schauen wir uns die Konkurrenz an, egal ob das gerade in Hongkong börsennotierte Zhipu und MiniMax im Inland oder OpenAI und Anthropic im Ausland, die sich um Investoren reißen. Um den teuren Rechenleistungskrieg aufrechtzuerhalten, kann selbst Elon Musk der Versuchung des Kapitals nicht widerstehen und hat erst vor wenigen Tagen 20 Milliarden Dollar für xAI eingesammelt. Doch DeepSeek hält bis heute an einem Rekord von „null externer Finanzierung“ fest.
Die Top Drei der kostenlosen App-Downloads werden bereits von den „drei Großen“ der inländischen Internetgiganten dominiert, während das einst führende DeepSeek still und leise auf Platz sieben abgerutscht ist. Inmitten der Konkurrenz, die ihre Allround-, Multimodal- und AI-Suchfähigkeiten am liebsten auf die Stirn schreiben würde, wirkt DeepSeek mit seinem minimalistischen 51,7-MB-Installationspaket, ohne Trendjagd und ohne aufwendige Promotion, sogar ohne visuelle Schlussfolgerung und Multimodalität, geradezu aus der Zeit gefallen. Doch genau das ist das Interessante daran. Oberflächlich betrachtet scheint es wirklich „abgehängt“ zu sein, doch tatsächlich bleibt das DeepSeek-Modell weiterhin die erste Wahl der meisten Plattformen. Als ich versuchte, DeepSeeks Aktivitäten des vergangenen Jahres zusammenzufassen und meinen Blick von dieser einzelnen Downloadliste auf die globale AI-Entwicklung zu lenken, um zu verstehen, warum es so gelassen bleibt und was das bald erscheinende V4 für neue Impulse in die Branche bringen wird, stellte ich fest, dass dieser „siebte Platz“ für DeepSeek keinerlei Bedeutung hat – es ist nach wie vor das „Gespenst“, das die großen Player nachts wach hält. Abgehängt? DeepSeek hat seinen eigenen Rhythmus Während die globalen AI-Giganten vom Kapital getrieben werden und durch Kommerzialisierung Profite erzielen müssen, wirkt DeepSeek wie ein einziger freier Akteur. Schauen wir uns die Konkurrenz an, egal ob das gerade in Hongkong börsennotierte Zhipu und MiniMax im Inland oder OpenAI und Anthropic im Ausland, die sich um Investoren reißen. Um den teuren Rechenleistungskrieg aufrechtzuerhalten, kann selbst Elon Musk der Versuchung des Kapitals nicht widerstehen und hat erst vor wenigen Tagen 20 Milliarden Dollar für xAI eingesammelt. Doch DeepSeek hält bis heute an einem Rekord von „null externer Finanzierung“ fest. 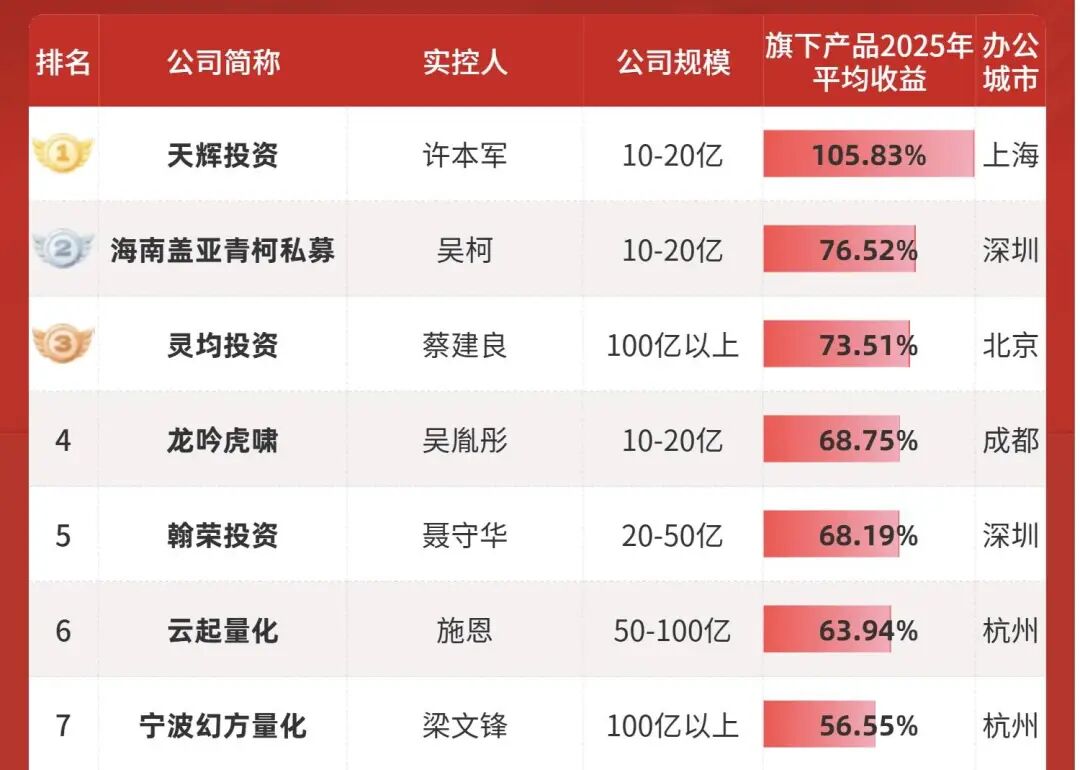 Im Jahresranking der hundert besten Private-Equity-Fonds liegt Quantum Fund auf Platz sieben beim durchschnittlichen Unternehmensgewinn,bei einem Volumen von über zehn Milliarden sogar auf Platz zwei In einer Zeit, in der alle schnell Geld machen und Investoren beeindrucken wollen, wagt DeepSeek es, zurückzufallen, weil im Hintergrund eine Super-„Gelddruckmaschine“ steht: Quantum Fund. Als Muttergesellschaft von DeepSeek erzielte dieser Quant-Fonds im vergangenen Jahr eine außergewöhnliche Rendite von 53 % und einen Gewinn von über 700 Millionen US-Dollar (umgerechnet rund 5 Milliarden RMB). Liang Wenfeng setzt dieses alte Geld direkt ein, um den neuen Traum von „DeepSeek AGI“ zu finanzieren. Dieses Modell verschafft DeepSeek einen geradezu luxuriösen Umgang mit Geld.
Im Jahresranking der hundert besten Private-Equity-Fonds liegt Quantum Fund auf Platz sieben beim durchschnittlichen Unternehmensgewinn,bei einem Volumen von über zehn Milliarden sogar auf Platz zwei In einer Zeit, in der alle schnell Geld machen und Investoren beeindrucken wollen, wagt DeepSeek es, zurückzufallen, weil im Hintergrund eine Super-„Gelddruckmaschine“ steht: Quantum Fund. Als Muttergesellschaft von DeepSeek erzielte dieser Quant-Fonds im vergangenen Jahr eine außergewöhnliche Rendite von 53 % und einen Gewinn von über 700 Millionen US-Dollar (umgerechnet rund 5 Milliarden RMB). Liang Wenfeng setzt dieses alte Geld direkt ein, um den neuen Traum von „DeepSeek AGI“ zu finanzieren. Dieses Modell verschafft DeepSeek einen geradezu luxuriösen Umgang mit Geld. 
Kein Einfluss von Investoren.
Kein Großkonzernsyndrom: Viele Labore, die enorme Finanzierungen erhalten haben, verfallen in trügerischen Wohlstand und interne Konflikte, wie zuletzt immer wieder bei Thinking Machine Lab mit vielen Berichten über Kündigungen oder bei Metas AI-Labor mit allerlei Gerüchten.
Verantwortung nur für die Technik: Da kein äußerer Bewertungsdruck besteht, muss DeepSeek keine All-in-One-App überhastet veröffentlichen, um die Bilanz zu schönen, noch muss es dem Multimodalitäts-Hype hinterherlaufen. Es muss nur der Technik gerecht werden, nicht der Finanzbilanz. Das App-Store-Downloadranking ist für Start-ups, die VC die „tägliche Nutzerzahl“ beweisen müssen, überlebenswichtig. Für ein Labor, das nur für AI-Entwicklung verantwortlich ist, keine Geldsorgen hat und sich nicht von KPIs steuern lassen will, sind diese Marktrankings vielleicht der beste Schutz, um konzentriert und unbeeinflusst von äußerem Lärm zu bleiben. Außerdem, laut Bericht von QuestMobile, ist DeepSeeks Einfluss keineswegs „abgehängt“. Lebensverändernd und treibende Kraft im globalen AI-Wettrüsten Auch wenn es DeepSeek vielleicht völlig egal ist, ob wir längst andere, praktischere AI-Anwendungen nutzen, so ist der Einfluss des vergangenen Jahres doch in allen Branchen spürbar. Das „DeepSeek-Beben“ im Silicon Valley Das ursprüngliche DeepSeek war nicht nur ein nützliches Werkzeug, sondern ein Trendbarometer, das mit besonders effizienter und kostengünstiger Herangehensweise den von Silicon-Valley-Giganten errichteten Mythos der hohen Eintrittsbarrieren zerstörte.
Außerdem, laut Bericht von QuestMobile, ist DeepSeeks Einfluss keineswegs „abgehängt“. Lebensverändernd und treibende Kraft im globalen AI-Wettrüsten Auch wenn es DeepSeek vielleicht völlig egal ist, ob wir längst andere, praktischere AI-Anwendungen nutzen, so ist der Einfluss des vergangenen Jahres doch in allen Branchen spürbar. Das „DeepSeek-Beben“ im Silicon Valley Das ursprüngliche DeepSeek war nicht nur ein nützliches Werkzeug, sondern ein Trendbarometer, das mit besonders effizienter und kostengünstiger Herangehensweise den von Silicon-Valley-Giganten errichteten Mythos der hohen Eintrittsbarrieren zerstörte.  Wenn das AI-Wettrennen vor einem Jahr noch aus „Wer hat mehr Grafikkarten, wer die größeren Modellparameter“ bestand, hat DeepSeek das Regelwerk radikal verändert. In der letzten veröffentlichten Zusammenfassung von OpenAI und ihrem Inhouse-Team (The Prompt) mussten sie einräumen, dass die Veröffentlichung von DeepSeek R1 das AI-Wettrennen damals „stark erschüttert“ hat (jolted) und sogar als „seismischer Schock“ (seismic shock) bezeichnet wurde. DeepSeek beweist immer wieder durch Taten, dass Spitzenmodellfähigkeiten nicht durch teure Rechenleistung erkauft werden müssen. Laut einer aktuellen Analyse des ICIS-Informationsdienstes hat DeepSeeks Aufstieg das Dogma der Rechenleistungsabhängigkeit vollständig aufgebrochen. Es zeigte der Welt, dass auch unter Chip-Beschränkungen und extrem begrenzten Ressourcen Modelle mit US-Spitzensystemen mithalten können.
Wenn das AI-Wettrennen vor einem Jahr noch aus „Wer hat mehr Grafikkarten, wer die größeren Modellparameter“ bestand, hat DeepSeek das Regelwerk radikal verändert. In der letzten veröffentlichten Zusammenfassung von OpenAI und ihrem Inhouse-Team (The Prompt) mussten sie einräumen, dass die Veröffentlichung von DeepSeek R1 das AI-Wettrennen damals „stark erschüttert“ hat (jolted) und sogar als „seismischer Schock“ (seismic shock) bezeichnet wurde. DeepSeek beweist immer wieder durch Taten, dass Spitzenmodellfähigkeiten nicht durch teure Rechenleistung erkauft werden müssen. Laut einer aktuellen Analyse des ICIS-Informationsdienstes hat DeepSeeks Aufstieg das Dogma der Rechenleistungsabhängigkeit vollständig aufgebrochen. Es zeigte der Welt, dass auch unter Chip-Beschränkungen und extrem begrenzten Ressourcen Modelle mit US-Spitzensystemen mithalten können.  Das hat das globale AI-Wettrennen von „Wer baut das intelligenteste Modell“ zu „Wer kann Modelle effizienter, günstiger und einfacher bereitstellen“ verschoben. Das „andere“ Wachstum im Microsoft-Bericht Während sich die Silicon-Valley-Giganten noch um zahlende Abonnenten streiten, beginnt DeepSeek in den von den großen Playern vergessenen Regionen Wurzeln zu schlagen. Im letzten Woche veröffentlichten „2025 Global AI Adoption Report“ von Microsoft wurde der Aufstieg von DeepSeek als eine der „überraschendsten Entwicklungen 2025“ genannt. Der Bericht liefert dabei interessante Zahlen:
Das hat das globale AI-Wettrennen von „Wer baut das intelligenteste Modell“ zu „Wer kann Modelle effizienter, günstiger und einfacher bereitstellen“ verschoben. Das „andere“ Wachstum im Microsoft-Bericht Während sich die Silicon-Valley-Giganten noch um zahlende Abonnenten streiten, beginnt DeepSeek in den von den großen Playern vergessenen Regionen Wurzeln zu schlagen. Im letzten Woche veröffentlichten „2025 Global AI Adoption Report“ von Microsoft wurde der Aufstieg von DeepSeek als eine der „überraschendsten Entwicklungen 2025“ genannt. Der Bericht liefert dabei interessante Zahlen:
Hohe Nutzung in Afrika: Dank DeepSeeks kostenloser Strategie und Open-Source-Charakter entfallen teure Abogebühren und Kreditkartenhürden. Die Nutzung in Afrika liegt zwei- bis viermal so hoch wie in anderen Regionen.
Marktdurchdringung in restriktiven Regionen: In Gebieten, in denen US-Tech-Giganten kaum vertreten sind oder deren Dienste beschränkt sind, ist DeepSeek fast die einzige Option. Daten zeigen einen Marktanteil von 89 % im Inland, 56 % in Belarus und 49 % in Kuba. Auch Microsoft musste im Bericht einräumen, dass DeepSeeks Erfolg zeigt, dass die Verbreitung von AI nicht nur von der Stärke des Modells abhängt, sondern davon, wer es sich leisten kann. Die nächste Milliarde AI-Nutzer könnte nicht aus den klassischen Technologiezentren stammen, sondern aus Regionen, die von DeepSeek abgedeckt werden. Europa: Wir wollen auch ein DeepSeek Nicht nur im Silicon Valley – DeepSeeks Einfluss reicht um den Globus, auch Europa ist da keine Ausnahme. Europa war lange Zeit passiver Nutzer amerikanischer AI, auch wenn es mit Mistral ein eigenes Modell gab, das aber kaum Beachtung fand. DeepSeeks Erfolg zeigt den Europäern einen neuen Weg: Wenn ein chinesisches Labor mit begrenzten Ressourcen das schafft, warum dann nicht auch Europa?
Die nächste Milliarde AI-Nutzer könnte nicht aus den klassischen Technologiezentren stammen, sondern aus Regionen, die von DeepSeek abgedeckt werden. Europa: Wir wollen auch ein DeepSeek Nicht nur im Silicon Valley – DeepSeeks Einfluss reicht um den Globus, auch Europa ist da keine Ausnahme. Europa war lange Zeit passiver Nutzer amerikanischer AI, auch wenn es mit Mistral ein eigenes Modell gab, das aber kaum Beachtung fand. DeepSeeks Erfolg zeigt den Europäern einen neuen Weg: Wenn ein chinesisches Labor mit begrenzten Ressourcen das schafft, warum dann nicht auch Europa?  Laut einem aktuellen Bericht des Wired-Magazins herrscht in der europäischen Tech-Szene jetzt ein regelrechter Wettbewerb, um ein „europäisches DeepSeek“ zu schaffen. Viele europäische Entwickler arbeiten an Open-Source-Großmodellen, darunter das Projekt SOOFI, das explizit sagt: „Wir werden Europas DeepSeek.“ DeepSeeks Einfluss im vergangenen Jahr hat auch die europäische Sorge um „AI-Souveränität“ verschärft. Sie erkennen zunehmend, dass eine zu starke Abhängigkeit von amerikanischen Closed-Source-Modellen riskant ist und das effiziente, offene DeepSeek-Modell als Vorbild dient. Zum V4 gibt es folgende interessante Informationen Der Einfluss dauert an: Wenn R1 vor einem Jahr DeepSeeks Demonstration für die AI-Branche war, könnte das kommende V4 erneut für Überraschungen sorgen. Basierend auf jüngsten Leaks und technischen Veröffentlichungen haben wir die wichtigsten Hinweise zu V4 zusammengefasst. 1. Neues Modell MODEL1 geleakt
Laut einem aktuellen Bericht des Wired-Magazins herrscht in der europäischen Tech-Szene jetzt ein regelrechter Wettbewerb, um ein „europäisches DeepSeek“ zu schaffen. Viele europäische Entwickler arbeiten an Open-Source-Großmodellen, darunter das Projekt SOOFI, das explizit sagt: „Wir werden Europas DeepSeek.“ DeepSeeks Einfluss im vergangenen Jahr hat auch die europäische Sorge um „AI-Souveränität“ verschärft. Sie erkennen zunehmend, dass eine zu starke Abhängigkeit von amerikanischen Closed-Source-Modellen riskant ist und das effiziente, offene DeepSeek-Modell als Vorbild dient. Zum V4 gibt es folgende interessante Informationen Der Einfluss dauert an: Wenn R1 vor einem Jahr DeepSeeks Demonstration für die AI-Branche war, könnte das kommende V4 erneut für Überraschungen sorgen. Basierend auf jüngsten Leaks und technischen Veröffentlichungen haben wir die wichtigsten Hinweise zu V4 zusammengefasst. 1. Neues Modell MODEL1 geleakt
Zum einjährigen Jubiläum von DeepSeek-R1 tauchten im offiziellen GitHub-Repository Hinweise auf ein neues Modell mit dem Codenamen „MODEL1“ auf. Im Code erscheint „MODEL1“ als eigenständiger Branch neben „V32“ (DeepSeek-V3.2), was darauf hindeutet, dass „MODEL1“ keine gemeinsamen Parameter oder Infrastrukturen mit der V3-Serie teilt, sondern einen neuen, unabhängigen technischen Weg einschlägt.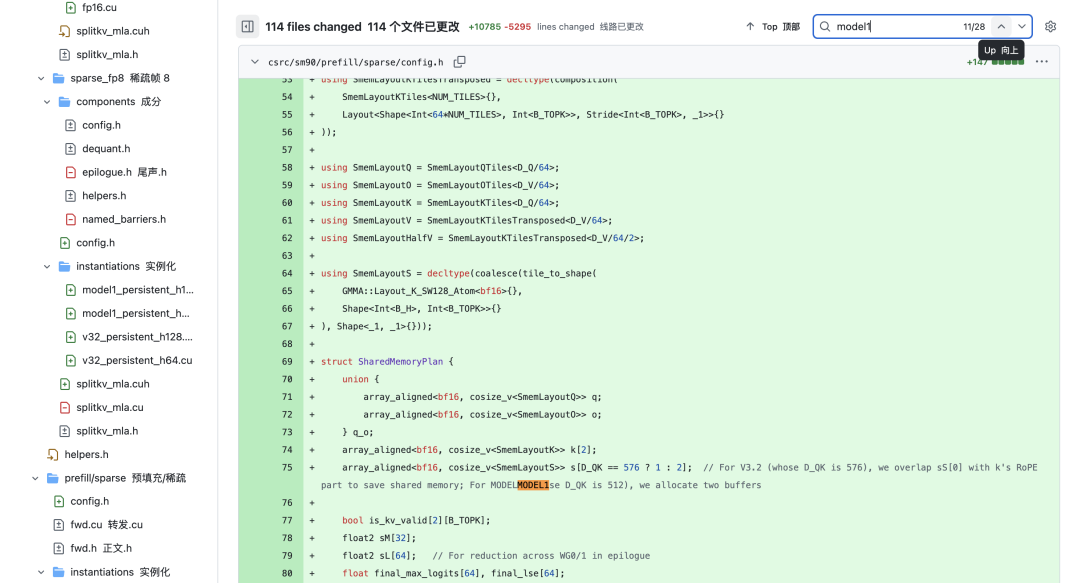 Basierend auf früheren Leaks und Code-Schnipseln haben wir folgende mögliche technische Merkmale von „MODEL1“ identifiziert:
Basierend auf früheren Leaks und Code-Schnipseln haben wir folgende mögliche technische Merkmale von „MODEL1“ identifiziert:  3. Kernkompetenz: Code und ultralanger Kontext Da allgemeine KI-Konversationen immer ähnlicher werden, wählt V4 einen härteren Ansatz: produktionsreife Code-Fähigkeiten. Quellen nah an DeepSeek berichten, dass V4 nicht bei den starken Benchmark-Resultaten von V3.2 stehen bleibt, sondern in internen Tests die Code-Generierungs- und Verarbeitungsfähigkeiten von Claude (Anthropic) und GPT (OpenAI) sogar übertroffen hat.
3. Kernkompetenz: Code und ultralanger Kontext Da allgemeine KI-Konversationen immer ähnlicher werden, wählt V4 einen härteren Ansatz: produktionsreife Code-Fähigkeiten. Quellen nah an DeepSeek berichten, dass V4 nicht bei den starken Benchmark-Resultaten von V3.2 stehen bleibt, sondern in internen Tests die Code-Generierungs- und Verarbeitungsfähigkeiten von Claude (Anthropic) und GPT (OpenAI) sogar übertroffen hat.  Noch wichtiger: V4 will einen großen Schwachpunkt aktueller Coding-AIs lösen – die Verarbeitung von „ultralangen Code-Prompts“. Das bedeutet, dass V4 nicht länger nur ein Assistent ist, der ein paar Zeilen Skript schreibt, sondern komplexe Softwareprojekte und große Codebasen verstehen kann. Um das zu erreichen, wurde auch der Trainingsprozess verbessert, damit das Modell bei der Verarbeitung großer Datenmengen nicht mit der Zeit „degeneriert“. 4. Schlüsseltechnologie: Engram Noch wichtiger als das V4-Modell selbst isteine letzte Woche gemeinsam mit der Peking-Universität veröffentlichte, gewichtige Publikation von DeepSeek. Darin wurde die eigentliche Trumpfkarte enthüllt, mit der DeepSeek auch bei limitierter Rechenleistung immer wieder durchbricht: eine neue Technologie namens „Engram“ (Gedächtnisspur/bedingtes Gedächtnis).
Noch wichtiger: V4 will einen großen Schwachpunkt aktueller Coding-AIs lösen – die Verarbeitung von „ultralangen Code-Prompts“. Das bedeutet, dass V4 nicht länger nur ein Assistent ist, der ein paar Zeilen Skript schreibt, sondern komplexe Softwareprojekte und große Codebasen verstehen kann. Um das zu erreichen, wurde auch der Trainingsprozess verbessert, damit das Modell bei der Verarbeitung großer Datenmengen nicht mit der Zeit „degeneriert“. 4. Schlüsseltechnologie: Engram Noch wichtiger als das V4-Modell selbst isteine letzte Woche gemeinsam mit der Peking-Universität veröffentlichte, gewichtige Publikation von DeepSeek. Darin wurde die eigentliche Trumpfkarte enthüllt, mit der DeepSeek auch bei limitierter Rechenleistung immer wieder durchbricht: eine neue Technologie namens „Engram“ (Gedächtnisspur/bedingtes Gedächtnis). 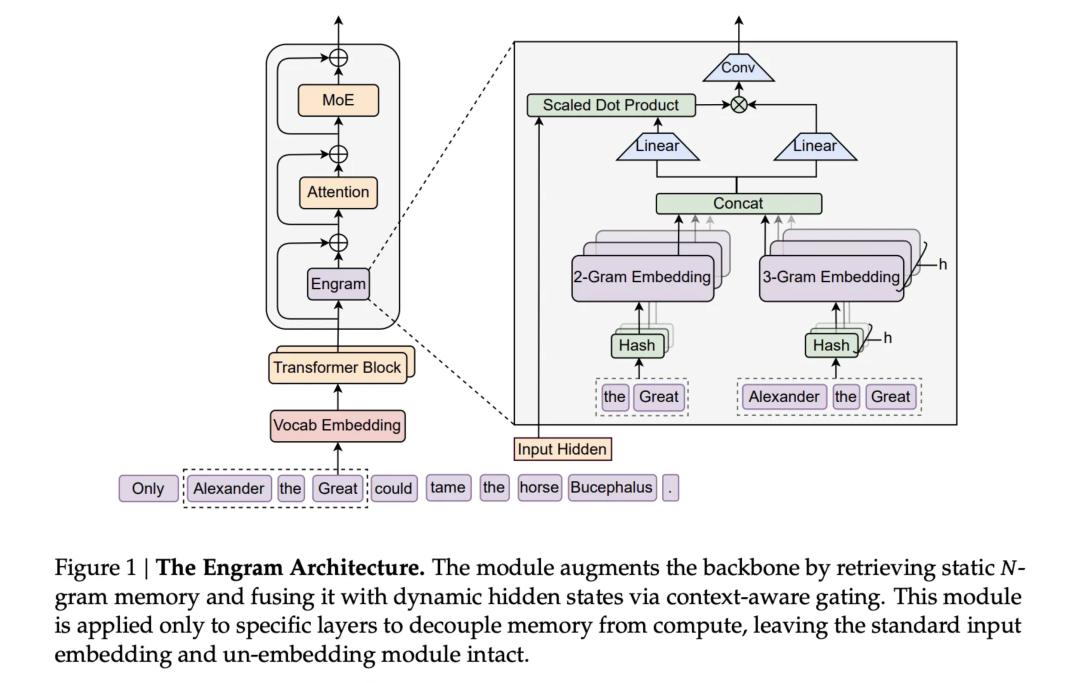 HBM (High Bandwidth Memory) ist eines der Schlüsselgebiete im globalen AI-Rechenleistungswettbewerb. Während andere auf H100-GPUs setzen, um mehr Speicher zu stapeln, geht DeepSeek erneut einen ungewöhnlichen Weg.
HBM (High Bandwidth Memory) ist eines der Schlüsselgebiete im globalen AI-Rechenleistungswettbewerb. Während andere auf H100-GPUs setzen, um mehr Speicher zu stapeln, geht DeepSeek erneut einen ungewöhnlichen Weg.
Entkopplung von Berechnung und Gedächtnis: Aktuelle Modelle benötigen oft teure Rechenleistung, um grundlegende Informationen abzurufen. Engram erlaubt dem Modell einen effizienten Zugriff auf diese Informationen, ohne jedes Mal Rechenleistung zu verschwenden.
Die eingesparte Rechenleistung kann dann gezielt für komplexere High-Level-Reasoning-Aufgaben genutzt werden.
Laut Forschern kann diese Technik die GPU-Speicherbeschränkungen umgehen und ermöglicht eine aggressive Erweiterung der Modellparameter. Vor dem Hintergrund knapper Grafikkartenressourcen macht die DeepSeek-Publikation deutlich: Sie haben nie darauf gesetzt, allein durch Hardware-Stacking zu gewinnen. DeepSeeks Entwicklung des vergangenen Jahres war im Kern das Lösen branchenüblicher AI-Probleme auf unkonventionelle Art. Es hat in einem Jahr 5 Milliarden verdient, könnte damit tausende DeepSeek R1-Modelle trainieren, aber statt auf mehr Rechenleistung oder Börsengänge zu setzen, forscht es daran, wie günstiger Speicher teuren HBM ersetzen kann. Im letzten Jahr hat es den Traffic für Allround-Modelle fast komplett aufgegeben und sich inmitten monatlicher und wöchentlicher Updates der Konkurrenz ganz auf Inferenzmodelle und deren wissenschaftliche Weiterentwicklung konzentriert. Diese Entscheidungen erscheinen kurzfristig „falsch“: Ohne Finanzierung – wie mit OpenAI mithalten? Ohne multimodale All-in-One-Apps mit Bild- und Videogeneration – wie Nutzer halten? Solange das Skalierungsgesetz gilt, wie das stärkste Modell bauen, ohne Rechenleistung zu stapeln?
Vor dem Hintergrund knapper Grafikkartenressourcen macht die DeepSeek-Publikation deutlich: Sie haben nie darauf gesetzt, allein durch Hardware-Stacking zu gewinnen. DeepSeeks Entwicklung des vergangenen Jahres war im Kern das Lösen branchenüblicher AI-Probleme auf unkonventionelle Art. Es hat in einem Jahr 5 Milliarden verdient, könnte damit tausende DeepSeek R1-Modelle trainieren, aber statt auf mehr Rechenleistung oder Börsengänge zu setzen, forscht es daran, wie günstiger Speicher teuren HBM ersetzen kann. Im letzten Jahr hat es den Traffic für Allround-Modelle fast komplett aufgegeben und sich inmitten monatlicher und wöchentlicher Updates der Konkurrenz ganz auf Inferenzmodelle und deren wissenschaftliche Weiterentwicklung konzentriert. Diese Entscheidungen erscheinen kurzfristig „falsch“: Ohne Finanzierung – wie mit OpenAI mithalten? Ohne multimodale All-in-One-Apps mit Bild- und Videogeneration – wie Nutzer halten? Solange das Skalierungsgesetz gilt, wie das stärkste Modell bauen, ohne Rechenleistung zu stapeln?  Aber auf lange Sicht könnten diese „falschen“ Entscheidungen der Wegbereiter für DeepSeeks V4 und R2 sein. Das ist DeepSeeks Wesenskern: Während alle auf Ressourcen setzen, setzt es auf Effizienz; während alle Kommerzialisierung anstreben, jagt es technischen Extremen nach. Wird V4 diesen Weg fortsetzen oder sich doch dem „gesunden Menschenverstand“ beugen? Die Antwort gibt es vielleicht in den nächsten Wochen. Zumindest wissen wir jetzt: In der AI-Branche ist manchmal das Ungewöhnliche der eigentliche Standard. Das nächste Mal ist wieder DeepSeek-Time.
Aber auf lange Sicht könnten diese „falschen“ Entscheidungen der Wegbereiter für DeepSeeks V4 und R2 sein. Das ist DeepSeeks Wesenskern: Während alle auf Ressourcen setzen, setzt es auf Effizienz; während alle Kommerzialisierung anstreben, jagt es technischen Extremen nach. Wird V4 diesen Weg fortsetzen oder sich doch dem „gesunden Menschenverstand“ beugen? Die Antwort gibt es vielleicht in den nächsten Wochen. Zumindest wissen wir jetzt: In der AI-Branche ist manchmal das Ungewöhnliche der eigentliche Standard. Das nächste Mal ist wieder DeepSeek-Time.
DeepSeek trat mit R1 am gestrigen Tag vor einem Jahr (20.01.2025) überraschend auf die Bühne und zog sofort weltweite Aufmerksamkeit auf sich. Damals habe ich sämtliche Self-Hosting-Anleitungen durchforstet und zahlreiche Apps ausprobiert, die sich „XX - DeepSeek Fullpower-Version“ nannten, nur um DeepSeek reibungslos nutzen zu können. Ein Jahr später, um ehrlich zu sein, öffne ich DeepSeek deutlich seltener. Doubao kann suchen und Bilder generieren, Qianwen ist mit Taobao und Gaode verknüpft, Yuanbao bietet Echtzeit-Sprachdialoge und ein Content-Ökosystem für WeChat-Accounts; ganz zu schweigen von den SOTA-Modellprodukten wie ChatGPT und Gemini aus dem Ausland. Während diese All-in-One-AI-Assistenten ihre Funktionslisten immer weiter ausbauen, stelle ich mir ganz pragmatisch die Frage: „Wenn es etwas Bequemeres gibt, warum sollte ich dann noch bei DeepSeek bleiben?“ So ist DeepSeek auf meinem Handy von der ersten auf die zweite Seite gerutscht und von einer täglich geöffneten zu einer gelegentlich genutzten App geworden. Ein Blick auf das App Store-Ranking zeigt, dass diese „Abkehr“ offenbar nicht nur mein persönlicher Eindruck ist. Die Top Drei der kostenlosen App-Downloads werden bereits von den „drei Großen“ der inländischen Internetgiganten dominiert, während das einst führende DeepSeek still und leise auf Platz sieben abgerutscht ist. Inmitten der Konkurrenz, die ihre Allround-, Multimodal- und AI-Suchfähigkeiten am liebsten auf die Stirn schreiben würde, wirkt DeepSeek mit seinem minimalistischen 51,7-MB-Installationspaket, ohne Trendjagd und ohne aufwendige Promotion, sogar ohne visuelle Schlussfolgerung und Multimodalität, geradezu aus der Zeit gefallen. Doch genau das ist das Interessante daran. Oberflächlich betrachtet scheint es wirklich „abgehängt“ zu sein, doch tatsächlich bleibt das DeepSeek-Modell weiterhin die erste Wahl der meisten Plattformen. Als ich versuchte, DeepSeeks Aktivitäten des vergangenen Jahres zusammenzufassen und meinen Blick von dieser einzelnen Downloadliste auf die globale AI-Entwicklung zu lenken, um zu verstehen, warum es so gelassen bleibt und was das bald erscheinende V4 für neue Impulse in die Branche bringen wird, stellte ich fest, dass dieser „siebte Platz“ für DeepSeek keinerlei Bedeutung hat – es ist nach wie vor das „Gespenst“, das die großen Player nachts wach hält. Abgehängt? DeepSeek hat seinen eigenen Rhythmus Während die globalen AI-Giganten vom Kapital getrieben werden und durch Kommerzialisierung Profite erzielen müssen, wirkt DeepSeek wie ein einziger freier Akteur. Schauen wir uns die Konkurrenz an, egal ob das gerade in Hongkong börsennotierte Zhipu und MiniMax im Inland oder OpenAI und Anthropic im Ausland, die sich um Investoren reißen. Um den teuren Rechenleistungskrieg aufrechtzuerhalten, kann selbst Elon Musk der Versuchung des Kapitals nicht widerstehen und hat erst vor wenigen Tagen 20 Milliarden Dollar für xAI eingesammelt. Doch DeepSeek hält bis heute an einem Rekord von „null externer Finanzierung“ fest. Im Jahresranking der hundert besten Private-Equity-Fonds liegt Quantum Fund auf Platz sieben beim durchschnittlichen Unternehmensgewinn,bei einem Volumen von über zehn Milliarden sogar auf Platz zwei In einer Zeit, in der alle schnell Geld machen und Investoren beeindrucken wollen, wagt DeepSeek es, zurückzufallen, weil im Hintergrund eine Super-„Gelddruckmaschine“ steht: Quantum Fund. Als Muttergesellschaft von DeepSeek erzielte dieser Quant-Fonds im vergangenen Jahr eine außergewöhnliche Rendite von 53 % und einen Gewinn von über 700 Millionen US-Dollar (umgerechnet rund 5 Milliarden RMB). Liang Wenfeng setzt dieses alte Geld direkt ein, um den neuen Traum von „DeepSeek AGI“ zu finanzieren. Dieses Modell verschafft DeepSeek einen geradezu luxuriösen Umgang mit Geld. Kein Einfluss von Investoren.
Kein Großkonzernsyndrom: Viele Labore, die enorme Finanzierungen erhalten haben, verfallen in trügerischen Wohlstand und interne Konflikte, wie zuletzt immer wieder bei Thinking Machine Lab mit vielen Berichten über Kündigungen oder bei Metas AI-Labor mit allerlei Gerüchten.
Verantwortung nur für die Technik: Da kein äußerer Bewertungsdruck besteht, muss DeepSeek keine All-in-One-App überhastet veröffentlichen, um die Bilanz zu schönen, noch muss es dem Multimodalitäts-Hype hinterherlaufen. Es muss nur der Technik gerecht werden, nicht der Finanzbilanz. Das App-Store-Downloadranking ist für Start-ups, die VC die „tägliche Nutzerzahl“ beweisen müssen, überlebenswichtig. Für ein Labor, das nur für AI-Entwicklung verantwortlich ist, keine Geldsorgen hat und sich nicht von KPIs steuern lassen will, sind diese Marktrankings vielleicht der beste Schutz, um konzentriert und unbeeinflusst von äußerem Lärm zu bleiben.
Außerdem, laut Bericht von QuestMobile, ist DeepSeeks Einfluss keineswegs „abgehängt“. Lebensverändernd und treibende Kraft im globalen AI-Wettrüsten Auch wenn es DeepSeek vielleicht völlig egal ist, ob wir längst andere, praktischere AI-Anwendungen nutzen, so ist der Einfluss des vergangenen Jahres doch in allen Branchen spürbar. Das „DeepSeek-Beben“ im Silicon Valley Das ursprüngliche DeepSeek war nicht nur ein nützliches Werkzeug, sondern ein Trendbarometer, das mit besonders effizienter und kostengünstiger Herangehensweise den von Silicon-Valley-Giganten errichteten Mythos der hohen Eintrittsbarrieren zerstörte. Wenn das AI-Wettrennen vor einem Jahr noch aus „Wer hat mehr Grafikkarten, wer die größeren Modellparameter“ bestand, hat DeepSeek das Regelwerk radikal verändert. In der letzten veröffentlichten Zusammenfassung von OpenAI und ihrem Inhouse-Team (The Prompt) mussten sie einräumen, dass die Veröffentlichung von DeepSeek R1 das AI-Wettrennen damals „stark erschüttert“ hat (jolted) und sogar als „seismischer Schock“ (seismic shock) bezeichnet wurde. DeepSeek beweist immer wieder durch Taten, dass Spitzenmodellfähigkeiten nicht durch teure Rechenleistung erkauft werden müssen. Laut einer aktuellen Analyse des ICIS-Informationsdienstes hat DeepSeeks Aufstieg das Dogma der Rechenleistungsabhängigkeit vollständig aufgebrochen. Es zeigte der Welt, dass auch unter Chip-Beschränkungen und extrem begrenzten Ressourcen Modelle mit US-Spitzensystemen mithalten können. Das hat das globale AI-Wettrennen von „Wer baut das intelligenteste Modell“ zu „Wer kann Modelle effizienter, günstiger und einfacher bereitstellen“ verschoben. Das „andere“ Wachstum im Microsoft-Bericht Während sich die Silicon-Valley-Giganten noch um zahlende Abonnenten streiten, beginnt DeepSeek in den von den großen Playern vergessenen Regionen Wurzeln zu schlagen. Im letzten Woche veröffentlichten „2025 Global AI Adoption Report“ von Microsoft wurde der Aufstieg von DeepSeek als eine der „überraschendsten Entwicklungen 2025“ genannt. Der Bericht liefert dabei interessante Zahlen: Hohe Nutzung in Afrika: Dank DeepSeeks kostenloser Strategie und Open-Source-Charakter entfallen teure Abogebühren und Kreditkartenhürden. Die Nutzung in Afrika liegt zwei- bis viermal so hoch wie in anderen Regionen.
Marktdurchdringung in restriktiven Regionen: In Gebieten, in denen US-Tech-Giganten kaum vertreten sind oder deren Dienste beschränkt sind, ist DeepSeek fast die einzige Option. Daten zeigen einen Marktanteil von 89 % im Inland, 56 % in Belarus und 49 % in Kuba. Auch Microsoft musste im Bericht einräumen, dass DeepSeeks Erfolg zeigt, dass die Verbreitung von AI nicht nur von der Stärke des Modells abhängt, sondern davon, wer es sich leisten kann.
Die nächste Milliarde AI-Nutzer könnte nicht aus den klassischen Technologiezentren stammen, sondern aus Regionen, die von DeepSeek abgedeckt werden. Europa: Wir wollen auch ein DeepSeek Nicht nur im Silicon Valley – DeepSeeks Einfluss reicht um den Globus, auch Europa ist da keine Ausnahme. Europa war lange Zeit passiver Nutzer amerikanischer AI, auch wenn es mit Mistral ein eigenes Modell gab, das aber kaum Beachtung fand. DeepSeeks Erfolg zeigt den Europäern einen neuen Weg: Wenn ein chinesisches Labor mit begrenzten Ressourcen das schafft, warum dann nicht auch Europa? Laut einem aktuellen Bericht des Wired-Magazins herrscht in der europäischen Tech-Szene jetzt ein regelrechter Wettbewerb, um ein „europäisches DeepSeek“ zu schaffen. Viele europäische Entwickler arbeiten an Open-Source-Großmodellen, darunter das Projekt SOOFI, das explizit sagt: „Wir werden Europas DeepSeek.“ DeepSeeks Einfluss im vergangenen Jahr hat auch die europäische Sorge um „AI-Souveränität“ verschärft. Sie erkennen zunehmend, dass eine zu starke Abhängigkeit von amerikanischen Closed-Source-Modellen riskant ist und das effiziente, offene DeepSeek-Modell als Vorbild dient. Zum V4 gibt es folgende interessante Informationen Der Einfluss dauert an: Wenn R1 vor einem Jahr DeepSeeks Demonstration für die AI-Branche war, könnte das kommende V4 erneut für Überraschungen sorgen. Basierend auf jüngsten Leaks und technischen Veröffentlichungen haben wir die wichtigsten Hinweise zu V4 zusammengefasst. 1. Neues Modell MODEL1 geleakt Zum einjährigen Jubiläum von DeepSeek-R1 tauchten im offiziellen GitHub-Repository Hinweise auf ein neues Modell mit dem Codenamen „MODEL1“ auf. Im Code erscheint „MODEL1“ als eigenständiger Branch neben „V32“ (DeepSeek-V3.2), was darauf hindeutet, dass „MODEL1“ keine gemeinsamen Parameter oder Infrastrukturen mit der V3-Serie teilt, sondern einen neuen, unabhängigen technischen Weg einschlägt.
Basierend auf früheren Leaks und Code-Schnipseln haben wir folgende mögliche technische Merkmale von „MODEL1“ identifiziert: - Der Code zeigt eine völlig neue KV-Cache-Layoutstrategie und neue Mechanismen für Sparsity-Handling.
- Im FP8-Decoding wurden mehrere gezielte Speicheroptimierungen vorgenommen, die auf eine höhere Inferenz-Effizienz und geringeren GPU-Speicherbedarf hindeuten.
- Frühere Leaks besagen, dass V4 bereits über den Code-Fähigkeiten von Claude und GPT liegt und komplexe Projektarchitektur und große Codebasen handhaben kann.
3. Kernkompetenz: Code und ultralanger Kontext Da allgemeine KI-Konversationen immer ähnlicher werden, wählt V4 einen härteren Ansatz: produktionsreife Code-Fähigkeiten. Quellen nah an DeepSeek berichten, dass V4 nicht bei den starken Benchmark-Resultaten von V3.2 stehen bleibt, sondern in internen Tests die Code-Generierungs- und Verarbeitungsfähigkeiten von Claude (Anthropic) und GPT (OpenAI) sogar übertroffen hat. Noch wichtiger: V4 will einen großen Schwachpunkt aktueller Coding-AIs lösen – die Verarbeitung von „ultralangen Code-Prompts“. Das bedeutet, dass V4 nicht länger nur ein Assistent ist, der ein paar Zeilen Skript schreibt, sondern komplexe Softwareprojekte und große Codebasen verstehen kann. Um das zu erreichen, wurde auch der Trainingsprozess verbessert, damit das Modell bei der Verarbeitung großer Datenmengen nicht mit der Zeit „degeneriert“. 4. Schlüsseltechnologie: Engram Noch wichtiger als das V4-Modell selbst isteine letzte Woche gemeinsam mit der Peking-Universität veröffentlichte, gewichtige Publikation von DeepSeek. Darin wurde die eigentliche Trumpfkarte enthüllt, mit der DeepSeek auch bei limitierter Rechenleistung immer wieder durchbricht: eine neue Technologie namens „Engram“ (Gedächtnisspur/bedingtes Gedächtnis). HBM (High Bandwidth Memory) ist eines der Schlüsselgebiete im globalen AI-Rechenleistungswettbewerb. Während andere auf H100-GPUs setzen, um mehr Speicher zu stapeln, geht DeepSeek erneut einen ungewöhnlichen Weg. Entkopplung von Berechnung und Gedächtnis: Aktuelle Modelle benötigen oft teure Rechenleistung, um grundlegende Informationen abzurufen. Engram erlaubt dem Modell einen effizienten Zugriff auf diese Informationen, ohne jedes Mal Rechenleistung zu verschwenden.
Die eingesparte Rechenleistung kann dann gezielt für komplexere High-Level-Reasoning-Aufgaben genutzt werden.
Laut Forschern kann diese Technik die GPU-Speicherbeschränkungen umgehen und ermöglicht eine aggressive Erweiterung der Modellparameter.
Vor dem Hintergrund knapper Grafikkartenressourcen macht die DeepSeek-Publikation deutlich: Sie haben nie darauf gesetzt, allein durch Hardware-Stacking zu gewinnen. DeepSeeks Entwicklung des vergangenen Jahres war im Kern das Lösen branchenüblicher AI-Probleme auf unkonventionelle Art. Es hat in einem Jahr 5 Milliarden verdient, könnte damit tausende DeepSeek R1-Modelle trainieren, aber statt auf mehr Rechenleistung oder Börsengänge zu setzen, forscht es daran, wie günstiger Speicher teuren HBM ersetzen kann. Im letzten Jahr hat es den Traffic für Allround-Modelle fast komplett aufgegeben und sich inmitten monatlicher und wöchentlicher Updates der Konkurrenz ganz auf Inferenzmodelle und deren wissenschaftliche Weiterentwicklung konzentriert. Diese Entscheidungen erscheinen kurzfristig „falsch“: Ohne Finanzierung – wie mit OpenAI mithalten? Ohne multimodale All-in-One-Apps mit Bild- und Videogeneration – wie Nutzer halten? Solange das Skalierungsgesetz gilt, wie das stärkste Modell bauen, ohne Rechenleistung zu stapeln? Aber auf lange Sicht könnten diese „falschen“ Entscheidungen der Wegbereiter für DeepSeeks V4 und R2 sein. Das ist DeepSeeks Wesenskern: Während alle auf Ressourcen setzen, setzt es auf Effizienz; während alle Kommerzialisierung anstreben, jagt es technischen Extremen nach. Wird V4 diesen Weg fortsetzen oder sich doch dem „gesunden Menschenverstand“ beugen? Die Antwort gibt es vielleicht in den nächsten Wochen. Zumindest wissen wir jetzt: In der AI-Branche ist manchmal das Ungewöhnliche der eigentliche Standard. Das nächste Mal ist wieder DeepSeek-Time. 
0
0
Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
PoolX: Locked to Earn
APR von bis zu 10%. Mehr verdienen, indem Sie mehr Lockedn.
Jetzt Lockedn!
Das könnte Ihnen auch gefallen
River und Sui kooperieren zur Integration von Cross-Chain-Liquidität und der satUSD-Stablecoin
BlockchainReporter•2026/01/21 04:02
EUR/USD bleibt nahe 1,1750 stark, da der US-Dollar schwächer wird und der ZEW-Index Deutschlands steigt
101 finance•2026/01/21 03:28
Lee aus Südkorea spielt vorgeschlagene US-Zölle auf Chips herunter und warnt vor höheren Preisen
101 finance•2026/01/21 03:20
Capital One (COF) Q4-Ergebnisse: Erwartete Ergebnisse
101 finance•2026/01/21 03:20
Im Trend
MehrKrypto-Preise
MehrBitcoin
BTC
$89,373.89
-3.04%
Ethereum
ETH
$2,978.99
-6.33%
Tether USDt
USDT
$0.9990
-0.03%
BNB
BNB
$879.62
-5.01%
XRP
XRP
$1.9
-2.96%
USDC
USDC
$0.9999
+0.01%
Solana
SOL
$127.54
-4.43%
TRON
TRX
$0.2983
-4.00%
Dogecoin
DOGE
$0.1254
-1.80%
Cardano
ADA
$0.3581
-2.21%
Wie man PI verkauft
Bitget listet PI - Kaufen oder verkaufen Sie PI schnell auf Bitget!
Jetzt traden
Sie sind noch kein Bitgetter?Ein Willkommenspaket im Wert von 6200 USDT für neue benutzer!
Jetzt anmelden