Wenn Ingenieure intelligentere Modelle ablehnen: Der Wettlauf der KI-Inferenz, OpenAI wechselt auf eine neue „Waffe“

Der Markt für KI-Inferenz durchläuft einen tiefgreifenden Paradigmenwechsel – Geschwindigkeit, nicht Intelligenz, wird zum entscheidenden Faktor, für den Entwickler bereit sind zu zahlen. Diese Trendwende hat den bisher eher am Rand stehenden Chip-Hersteller Cerebras ins Rampenlicht katapultiert und OpenAI dazu gebracht, Milliarden von Dollar auf einen bald börsennotierten Wafer-Level-Chiphersteller zu setzen.
Laut einem ausführlichen Bericht der Branchenforschungsinstitut SemiAnalysis hat OpenAI mit Cerebras einen Rahmenvertrag über insgesamt 750 Megawatt Rechenleistung unterschrieben, potenziell erweiterbar auf 2 Gigawatt, was verbleibende Vertragsverpflichtungen in Höhe von 24,6 Milliarden US-Dollar bedeutet.
Das zentrale Argument dieser Transaktion lautet: Das GPT-5.3-Codex-Spark-Modell von OpenAI kann auf der Cerebras-Hardware für jeden Nutzer eine Generierungsgeschwindigkeit von 2.000 Token pro Sekunde erreichen – deutlich schneller als das, was GPU-Cluster auf Basis von HBM in puncto Interaktivität bieten können. Gleichzeitig steht Cerebras kurz vor dem IPO und ist nun eng mit OpenAI verbunden.
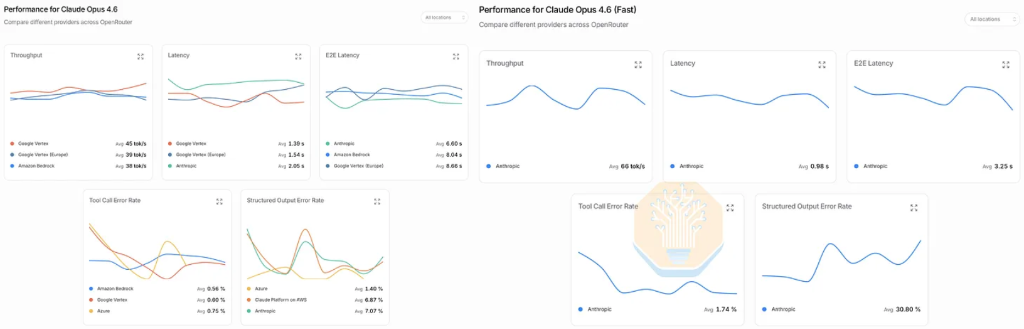
Die Marktsignale dieser Geschwindigkeitsrevolution sind deutlich. SemiAnalysis berichtet, dass 80% der KI-Ausgaben seines Teams (jährliche Spitzenwerte von 10 Millionen US-Dollar) auf den schnellen Modus Opus 4.6 von Anthropic entfallen – in diesem Modus wird ein 2,5-facher Interaktivitätsvorteil für einen sechsfachen Aufpreis bezahlt. Ein besonders überzeugendes Zeichen: Als Opus 4.7 veröffentlicht wurde, lehnten mehrere Ingenieure im Team ein Upgrade ab, da die neue Version den schnellen Modus nicht unterstützte. Dies war das erste Mal, dass das SemiAnalysis-Team bewusst auf fortgeschrittene Intelligenz verzichtete und stattdessen das schnellere Token-Generieren bevorzugte.
Geschwindigkeitsaufschlag: Entwickler stimmen mit ihrem Geldbeutel ab
Das Wettbewerbsumfeld im Inferenzmarkt wird entlang einer neuen Achse neu ausgerichtet.
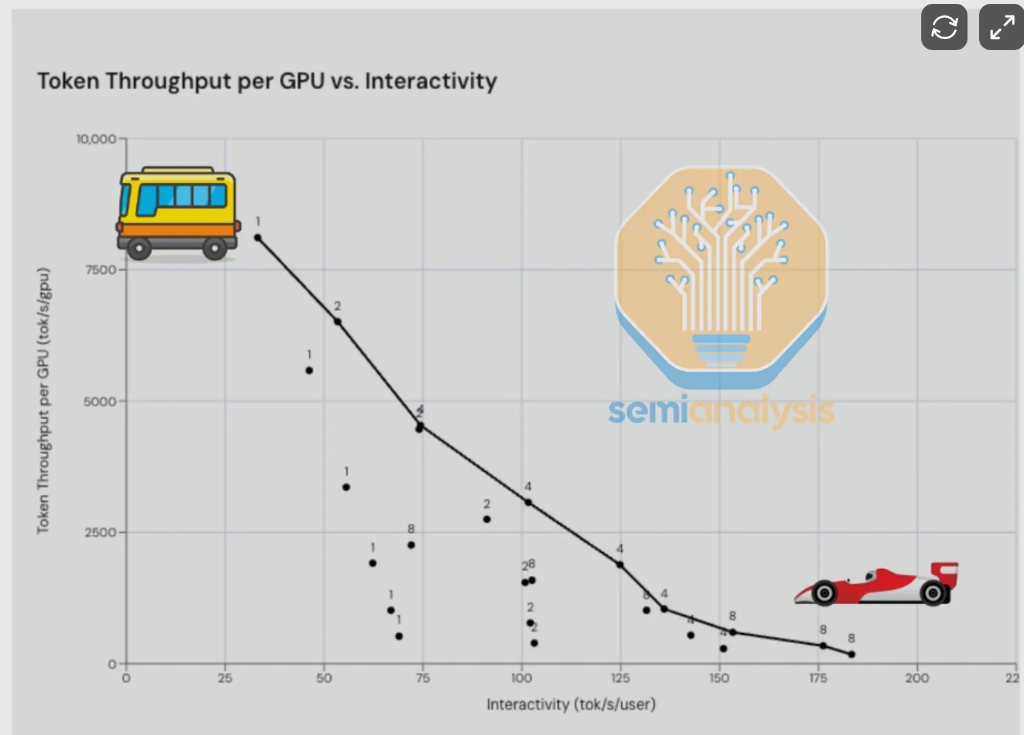
Wie Nvidia-CEO Jensen Huang auf der diesjährigen GTC-Konferenz wiederholt betonte, sind Durchsatz (Tokens pro GPU pro Sekunde) und Interaktivität (Tokens pro Nutzer pro Sekunde) die fundamentalen Trade-offs bei der Inferenz – ersteres bedient die Massenverarbeitung, letzteres definiert das Nutzererlebnis. SemiAnalysis vergleicht dies mit der Wahl zwischen „Bus und Ferrari“: Man kann viele Nutzer langsam bedienen oder einzelne Nutzer schnell.
Die Präferenz im Markt ist durch das Konsumverhalten bestätigt worden. Der schnelle Modus Opus 4.6 wurde zum profitabelsten Produkt-SKU von Anthropic, mit einem sechsfachen Preisaufschlag und etwa 2,5-facher Interaktivität – ein wesentlicher Treiber für das explosive ARR-Wachstum in diesem Jahr. Doch die von SemiAnalysis und OpenRouter gesammelten Daten zeigen, dass die Leistung dieses Modus jüngst nachgelassen hat: Die Interaktivität des Standard-Opus 4.6 liegt stabil bei etwa 40 tps, der schnelle Modus überschritt einst die 100 tps, fiel jedoch kürzlich auf etwa 70 tps – das tatsächliche Beschleunigungsverhältnis schrumpfte von 2,5-fach auf etwa 1,75-fach.
OpenAI und Anthropic haben diese differenzierten Bedürfnisse erkannt und versuchen, mit schnellen Modi, bevorzugten Modi oder Batch-Preisen das gesamte Spektrum abzudecken und das maximale Profitkombinationsmodell zu finden.
Wafer-Level-Chips: Technologische Logik eines riskanten Wettspiels
Cerebras’ zentrales Wagnis besteht darin, die physikalischen Grenzen der Lithographie zu überwinden und einen kompletten Wafer als einzigen Chip zu verwenden.
Die dritte Generation, WSE-3, wird nach dem TSMC-N5-Prozess gefertigt und integriert 44 GB SRAM auf einem Wafer bei einer Speicherbandbreite von 21 PB/s – tausendfach höher als HBM. Das Prinzip dahinter: extrem hohe Speicherbandbreite sorgt für extrem niedrige Speicherzugriffszeiten, sodass der WSE-3 bei kleinen Batches und geringer arithmetischer Intensität seine theoretische Rechenleistung voll entfaltet, während HBM-basierte GPUs in ähnlichen Szenarien oft „rechenleistungshungrig“ sind.
Allerdings geht diese Architektur mit erheblichen Nachteilen bei Rechendichte einher. SemiAnalysis stellt klar: Die tatsächliche dichte FP16-Leistung von WSE-3 beträgt nur 15,625 PFLOPS – das ist achtmal weniger als die von Cerebras beworbenen 125 PFLOPS, was der Annahme einer 8:1 unstrukturierten Sparsity zugrunde liegt. SemiAnalysis nennt das die „Feldman-Formel“ und zieht den Vergleich zur „Jensen-Mathematik“ von Nvidia, sieht aber Cerebras damit als weitergegangen.
Bei den Systemkosten schätzt SemiAnalysis die Materialkosten einer CS-3-Servereinheit (inkl. KVSS-CPU-Knoten) auf etwa 450.000 US-Dollar – deutlich über den reinen Chipkosten bei TSMC (ca. 20.000 US-Dollar je Wafer). Die hohen Kosten entstehen durch maßgeschneiderte Strommodule (von Vicor), Flüssigkeitskühlung und die speziellen Masken für jedes Wafer-Los.

Architektureinschränkung: Die geometrische Bandbreitenproblematik im Netzwerk
Die auffälligste Schwäche des WSE-3 ist die enorm begrenzte externe Bandbreite.
Jeder WSE-3 bietet nur 150 GB/s (1,2 Tb/s) externe Bandbreite – nur ein Sechstel dessen, was eine einzelne Nvidia Blackwell NVLink5-GPU mit 900 GB/s bieten kann. Diese Limitierung ist kein Designfehler, sondern eine systembedingte Restriktion der Wafer-Level-Architektur – SemiAnalysis bezeichnet das als „Inselproblem“.
Die Ursache liegt in der gleichmäßigen Stepp-Exposure-Technologie des Wafers. Der WSE-3 besteht aus 84 identischen Belichtungszellen (Dies), die alle identisch sein müssen, damit das 2D-Gitter zwischen den Dies funktioniert. Das SerDes-Phy kann nicht am Waferrand konzentriert werden – um die I/O-Bandbreite zu erhöhen, müsste in jedem Die Platz für Phy reserviert werden, doch die Phy im Inneren des Wafers können nicht mit der Außenwelt verbunden werden, was viel „Stranded Silicon“ verursacht. Außerdem führen Phy-Module zu „Lücken“ im Gitter und erhöhen Routing-Latenzen, was den Vorteil der Architektur schmälert.
Diese Bandbreitenbeschränkung limitiert die Fähigkeit von Cerebras, große Modelle zu bedienen. Für moderne Workloads mit mehr als einer Billion Parametern und Kontextfenster von einer Million Token muss Cerebras Modelle schichtweise auf mehrere Wafer verteilen und nur Aktivierungswerte zwischen den Wafern übertragen. Doch mit wachsender Modellgröße steigt die Zahl der benötigten Wafer linear, und die Festverzögerung pro Wafer-zu-Wafer-Übertragung summiert sich und gefährdet letztlich den Geschwindigkeitsvorteil.
SRAM-Expansion ist tot: Sorgen im Fahrplan
Eine weitere strukturelle Herausforderung für Cerebras ist die physikalische Begrenzung der SRAM-Dichte.
Von WSE-1 (TSMC 16nm, 18 GB SRAM) zu WSE-2 (7nm, 40 GB) gelang eine 2,2-fache Kapazitätssteigerung. Doch beim Übergang von WSE-2 (7nm) zu WSE-3 (5nm) wuchs die SRAM-Kapazität nur von 40 GB auf 44 GB (+10%), während die Zahl der Logiktransistoren um ca. 50% stieg. Die Daten von SemiAnalysis zeigen: Ab 5nm schrumpft die SRAM-Zellfläche bei TSMC von N3E gegenüber N5 kaum noch, und auch N2 und spätere Knoten bieten praktisch keine Verbesserung – die SRAM-Expansion ist tatsächlich zum Stillstand gekommen.
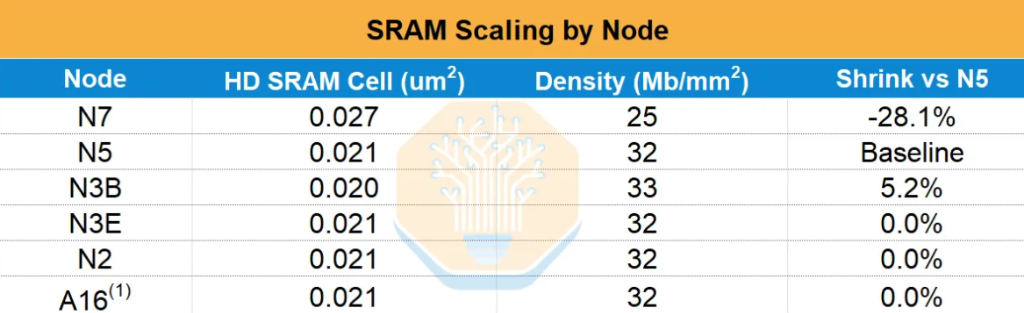
Das heißt, Cerebras kann in Zukunft die SRAM-Kapazität nur noch erhöhen, indem es auf fester Waferfläche Rechenfläche gegen Speicherfläche tauscht – ein strenger Nullsummen-Kompromiss. Das nächste CS-4-System wird weiter WSE-3 basierend auf N5 verwenden und die Leistung einzig durch höhere Stromaufnahme und Taktfrequenz steigern, während die SRAM-Kapazität unverändert bleibt.
Im Vergleich dazu kann Nvidia nach dem Groq-Kauf durch die Hybrid-Bonding-Technologie SRAM-Chips in Z-Richtung stapeln (LP40-Roadmap) und so die Limitation der flächigen Expansion umgehen. Cerebras erforscht ebenfalls vergleichbare Ansätze – etwa das Stapeln von DRAM-Wafern oder photonischen Interconnect-Wafern durch Hybrid-Bonding auf dem WSE. SemiAnalysis bleibt bei der technischen Machbarkeit und Zeitschiene jedoch vorsichtig: Wafer-Level-Hybrid-Bonding ist wegen thermomechanischer Belastungen und Bondwellen wesentlich komplexer als das Bonding konventioneller Chips.
OpenAI-Deal: Das zweischneidige Schwert eines Einzelkunden
Die Beziehung zwischen Cerebras und OpenAI geht weit über das gewöhnliche Verhältnis zwischen Lieferant und Kunde hinaus.
Nach Angaben von SemiAnalysis unter Berufung auf das S-1-Dokument wurde im Dezember 2025 ein Rahmenvertrag (MRA) geschlossen. OpenAI verpflichtet sich, zwischen 2026 und 2028 gestaffelt 750 Megawatt KI-Inferenz-Leistung zu beziehen, mit dreijährigen bis vierjährigen Einzelverträgen, verlängerbar auf bis zu fünf Jahre, und einer Option auf zusätzliche 1,25 Gigawatt. Am 31. Dezember 2025 betrugen die verbleibenden Verpflichtungen von Cerebras 24,6 Milliarden US-Dollar.
Im Kapitalgefüge spielt OpenAI drei Rollen: Es stellt Cerebras einen besicherten Betriebsmittelkredit von 1 Milliarde US-Dollar (6% Jahreszins; bei Rückzahlung in Form von Rechenleistung erlassen), hält 33,445 Millionen N-Aktien (ohne Stimmrecht) mit nahe Null Ausübungspreis, und könnte im vollständig verwässerten Szenario rund 12% der Cerebras-Anteile besitzen. Wird die MRA aus anderen Gründen als OpenAI beendet, muss Cerebras den gesamten Kredit und die Zinsen sofort zurückzahlen; OpenAI kann zudem direkt die Nutzung der Treuhandkontengelder steuern.
Diese Konstruktion bedeutet, dass die Wachstumsaussichten von Cerebras stark an einen Einzelkunden geknüpft sind. SemiAnalysis erwartet, dass Cerebras in den kommenden Jahren einen deutlichen Umsatzsprung machen wird – OpenAI ist der Hauptwachstumstreiber, birgt aber auch Risiken: Bis 2028 muss Cerebras mehr Server liefern, als die gesamte bisherige Ausbringung je erreicht hat; der Baufortschritt der Rechenzentren bleibt der größte Unsicherheitsfaktor.
Geschwindigkeit statt Intelligenz: Was ist dieser Deal wert?
Das bei Cerebras laufende OpenAI-Flaggschiff GPT-5.3-Codex-Spark ist nicht das echte GPT-5.3-Codex, sondern ein auf gpt-oss-120B basierendes, durch GPT-5.3-Codex distilliertes, kleineres Modell, dessen Parameterzahl mehr als zehnmal kleiner ist als beim Original.
SemiAnalysis bringt es deutlich auf den Punkt: Die Cerebras-Chips sind wirtschaftlich derzeit nur für relativ kleine Modelle besonders effizient. Für Workloads mit mehr als einer Billion Parametern und Kontextfenstern von einer Million Token würde OpenAI auf Cerebras erhebliche Mehrkosten bezahlen müssen und vermutlich weniger als 1.000 Token pro Sekunde tatsächlicher Interaktivität erreichen.
Doch hinter diesem Urteil steckt eine entscheidende Variable: Die Geschwindigkeit des Algorithmusfortschritts. SemiAnalysis schätzt, dass 120B-Parameter-Modelle in weniger als einem Jahr die GPT-5.5-Intelligenz erreichen könnten. Dann würde sich das Verhältnis von „Intelligenz gegen Geschwindigkeit“ grundlegend ändern – wie heute Entwickler lieber auf die höhere Intelligenz von Opus 4.7 verzichten und den schnellen Modus von Opus 4.6 behalten.
Die Anfangszusage von 750 Megawatt ist fix. Die entscheidende Frage lautet: Wenn die Intelligenz von 120B-Modellen das heutige Spitzenlevel erreicht, wird OpenAI die Optionsrechte ausüben und auf bis zu 2 Gigawatt oder noch mehr erweitern? Die Antwort darauf entscheidet, ob Cerebras den IPO-Bewertungsrahmen erfüllen kann – und sie definiert die nächste Phase der Inferenzkriege.
Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
Das könnte Ihnen auch gefallen
VOOI schwankt in 24 Stunden um 800,7 %: Extreme Preisschwankungen in einem Markt mit geringer Liquidität
BGSC schwankt innerhalb von 24 Stunden um 89,3 %: Token-Burn-Effekt treibt starke Preisschwankungen an